
Партия пенсионеров России
Региональное отделение по Республике Хакасия
- Главная
- Партия
- Контакты

Флаг Партии пенсионеров России

Кормилец местных поселенцев

Макет строящегося музея
Славлю трижды, которое будет
Здравствуйте, я ваша партия! Что впереди расстелется – всё позади останется.
Google создала базу из тысячей записей синтезированной речи
Опубликовано: 3 февраля 2019 01:02
Последние изменения: 3 февраля 2019 01:02
Радио
Свежие записи
- Милов на «Свободе» 09.08.2021
- Дискуссия: Невзоров, Шевченко _ Белковский между 07.08.2021
- Детали времени _ За пределами нормальности _ Яковенко 06.08.2021
- ВОЗ и ныне там _ Белковский 06.08.2021
- Один 06.08.2021
- Остатки цивилизованного имиджа _ Невзоров 02.08.2021
- Один 30.07.2021
- Сумерки запугивания 27.07.2021
- Один 23.07.2021
- Девушки ловушки 22.07.2021
- Григорий, у-лю-лю 21.07.2021
- Потери гражданского общества 20.07.2021
- Прогулка по райскому аду _ Заповедник 19.07.2021
- Ночь коротка 18.07.2021
- Верные не нужны, нужны продажные 16.07.2021
- Один 16.07.2021
- Интриги едросов 14.07.2021
- Трудности воображаемых люстраций _ Милов 12.07.2021
- Изнеможение от величия 12.07.2021
- Один 09.07.2021
- Дурных стихов простить нельзя 07.07.2021
- Мания реестров 07.07.2021
- Ордынские традиции 05.07.2021
- Улыбка усталой панды _ Наповал 05.07.2021
- Вялые паруса _ Перносчики плакатов _ Заповедник 177 05.07.2021
- Раздутый капюшон 03.07.2021
- Один 02.07.2021
- Линию горизонта украсть осталось 01.07.2021
- Нас снова выбрали Маруся, Роза , Рая _ Заповедник 28.06.2021
- Кремлевские истерички 27.06.2021
- Ночь коротка 27.06.2021
- Жёлтое и унылое на стене 26.06.2021
- Из лучших программ Шульман 26.06.2021
- Заговоры пауков _ О книге Андрея Остальского 26.06.2021
- Призовая контузия _ Янина Соколова 26.06.2021
Архивы публикаций
- Август 2021 (6)
- Июль 2021 (22)
- Июнь 2021 (36)
- Май 2021 (91)
- Апрель 2021 (142)
- Март 2021 (84)
- Февраль 2021 (124)
- Январь 2021 (94)
- Декабрь 2020 (138)
- Ноябрь 2020 (92)
- Октябрь 2020 (100)
- Сентябрь 2020 (56)
- Август 2020 (80)
- Июль 2020 (89)
- Июнь 2020 (78)
- Май 2020 (102)
- Апрель 2020 (135)
- Март 2020 (170)
- Февраль 2020 (217)
- Январь 2020 (246)
- Декабрь 2019 (215)
- Ноябрь 2019 (288)
- Октябрь 2019 (228)
- Сентябрь 2019 (229)
- Август 2019 (220)
- Июль 2019 (167)
- Июнь 2019 (125)
- Май 2019 (163)
- Апрель 2019 (246)
- Март 2019 (280)
- Февраль 2019 (214)
- Январь 2019 (173)
- Декабрь 2018 (159)
- Ноябрь 2018 (226)
- Октябрь 2018 (217)
- Сентябрь 2018 (141)
- Август 2018 (112)
- Июль 2018 (116)
- Июнь 2018 (101)
- Май 2018 (171)
- Апрель 2018 (138)
- Март 2018 (231)
- Февраль 2018 (241)
- Январь 2018 (272)
- Декабрь 2017 (292)
- Ноябрь 2017 (347)
- Октябрь 2017 (290)
- Сентябрь 2017 (314)
- Август 2017 (314)
- Июль 2017 (309)
- Июнь 2017 (310)
- Май 2017 (389)
- Апрель 2017 (274)
- Март 2017 (195)
- Февраль 2017 (251)
- Январь 2017 (11)
- Декабрь 2016 (207)
- Ноябрь 2016 (204)
- Октябрь 2016 (75)
- Сентябрь 2016 (68)
- Август 2016 (22)
- Июль 2016 (17)
- Июнь 2016 (35)
- Май 2016 (28)
- Апрель 2016 (39)
- Март 2016 (89)
- Март 2015 (1)
Рубрики сайта
Просмотры
- Как закалялась шваль – 1 670 Просмотры
- Печальный образ _ Чаплин в рясе – 1 758 Просмотры
- НАМЕДНИ-1950 – 11 406 Просмотры
- Керосиновое солнце / Путинизм как он есть – 9 290 Просмотры
- Не время улыбаться! – 8 871 Просмотры
- Если завтра как всегда – 8 166 Просмотры
- Борьба с нарушителями ДТП в Саудовской Аравии – 8 159 Просмотры
- Скончалась Лидия Аркадьевна, бабуля, которая очень сильно не любила Навального, пишет Медуза – 7 939 Просмотры
- Прошла демонстрация образцов новой формы для Росгвардии – 7 470 Просмотры
- Миллиардер из томской глубинки Денис Николаевич Штенгелов – 7 227 Просмотры
- «Чё ты как чмо, чё ты как черт, чё ты не патриот? Ты чё волчёнок?» – 6 199 Просмотры
- Ну-ка, Люся, отойди в сторонку – 5 726 Просмотры
О сайте
Формально под флагом Партии пенсионеров России*
Фактически — без политических амбиций.
Ментально — по возрасту и настроению
___
* 13 июн. 2019 г. — Верховный суд принял решение о ликвидации Партии пенсионеров России
___
Архив избранных публикаций
Олега Козлова
RHVoice Lab: как незрячие разработчики создают голоса для синтезатора речи
Год назад команда лаборатории решила синтезировать голос Артемия Лебедева для озвучки навигации незрячих людей в интернете. Сейчас в каталоге RHVoice восемь голосов, в том числе блогеров, стендап-комиков и театральных звезд.
Представьте на секунду, что этот текст вы не пробегаете глазами, пока допиваете кофе, а слушаете в выбранной озвучке, лишь примерно представляя, как выглядит верстка страницы. Тем не менее, именно так статью «прочитают» незрячие люди, в том числе энтузиасты RHVoice Lab.
RHVoice Lab – это некоммерческая лаборатория по созданию новых голосов для одноименного отечественного синтезатора речи. Его особенность в том, что он создан специально для слабовидящих и незрячих людей, для бытового использования. За год существования RHVoice Lab создала до десяти новых голосов, в том числе для английского и украинского языков. Благодаря команде проекта незрячие люди могут выбирать голос подходящего им тембра и звучания или «озвучивать» навигацию по интернету голосами известных людей.
Руководитель проекта Артём Плаксин рассказал, как появилась идея RHVoice Lab, как воссоздать голос Артемия Лебедева при помощи сервера от Selectel и можно ли быть программистом, если ты не видишь код.
Об отечественном синтезаторе речи и его создательнице — Ольге Яковлевой — на Хабре писали год назад. Если вы лишь примерно представляете, как работают синтезаторы речи, рекомендуем обратиться к этой статье.
RHVoice (ссылка на международный сайт) существует уже более 10 лет, облегчая жизнь незрячих и слабовидящих людей. С развитием искусственного интеллекта и голосовых помощников синтезаторами речи никого не удивишь — по запросу Алиса или Siri зачитают вам прогноз погоды или статью из «Википедии». Но RHVoice вместе с первым голосом — Александром — появился задолго до рождения Алисы.
Кроме того, сравнивать синтезаторы речи от Yandex или «Сбера» некорректно. RHVoice использует статистический параметрический синтез, основанный на скрытой Марковской модели. Это устаревший метод синтеза, который предварял нейронные сети. При таком виде синтеза сложнее добиться естественного звучания голоса — многое зависит от мастерства его создателей. Зато он позволяет использовать голоса из каталога RHVoice без подключения к интернету и на слабом устройстве.
RHVoice дает возможность полностью озвучить любое взаимодействие незрячего человека с компьютером: ввод системного пароля при входе в учетную запись и завершение сеанса работы, серфинг в интернете, общение в соцсетях, чтение книг, редакторская работа и остальное. Большая часть операций с компьютером, которые совершает человек, доступна, частично доступна или в перспективе доступна незрячему человеку. Ролики с котиками на YouTube не посмотреть, зато более информативный контент — те же интервью Дудя или новости Лебедева — можно и посмотреть, и лайкнуть, и прокомментировать. Во всем этом поможет синтезатор речи, встроенный в скринридер.
Скринридер (Screen reader) — это программа экранного доступа. Он по кусочкам разбирает интерфейсы программ, сайтов, текст и прочее и в специализированном виде подает на брайлевский дисплей или синтезатор речи. К таким программам относятся NVDA, Jaws, Talkback, VoiceOver.
Скринридер во многом работает как поисковые системы — парсит информацию по HTML-разметке. Люди обычно не задумываются, что стоит за заголовком, кнопками, текстом и хедером на сайте — они охватывают все визуально. Для незрячих людей правильная разметка, добавление лейблов очень важны, так как это позволяет скринридеру работать эффективнее, а синтезатору речи — озвучивать так, чтобы незрячий человек мог взаимодействовать с сайтом.
RHVoice продолжает развиваться: в июле вышел релиз версии 1.4.2 (подробнее об изменениях можно прочесть по ссылке). Одно из главных новшеств — замена библиотеки Sonic для ускорения голоса на собственное решение RHVoice. Незрячему человеку важно иметь гибкость в настройке синтеза речи: изменять тон, громкость, скорость воспроизведения без ущерба качеству и четкости речи. Поэтому большая часть улучшений направлена на достижение этой гибкости, замены устаревших решений на более современные.
Лаборатория RHVoice Lab появилась в 2020 года. До этого в каталоге RHVoice было четыре русскоязычных голоса, каждый из которых создала основательница проекта Ольга Яковлева.
Последние три года руководитель RHVoice Lab Артём Плаксин занимается некоммерческими социальными проектами для слабовидящих и незрячих людей. Будучи незрячим, он со школьных лет реализовывает полезные сервисы, онлайн-решения и прочее. Помимо RHVoice Lab, Артём руководит еще несколькими проектами. В их числе — сервис «Данные в данные», помогающий незрячим людям конвертировать изображения в текст, текст в речь и так далее; облачный сервис Tiflo Cloud — это альтернатива «Яндекс.Диску», которая доступна для незрячих людей; «Тифло Хост» – некоммерческая организация, занимающаяся развитием рунета для слепых.
Как отмечает Артём, изначально плана создавать целую библиотеку голосов не было. Начали с одного.
В апреле 2020 года я начал смотреть “Самые честные новости” на YouTube-канале Артемия Лебедева. И через некоторое время задался вопросом, а как бы он звучал в синтезированном варианте. Артемию 45 лет, но у него живой, ровный голос без хрипотцы и лишних призвуков. Говорит он быстро, четко, тембр приятный.
На тот момент команды, которая могла бы реализовать идею, не было. Понимания, как выстроить процесс, тоже. Зато была дружба с Бекой Гозалишвили, незрячим разработчиком, который занимался языковым модулем для грузинского языка в рамках проекта RHVoice. Он рассказал, как можно реализовать задумку, и в итоге вошел в команду лаборатории в качестве технического специалиста.
Вся команда RHVoice Lab состоит из четырех человек. Это Артём Плаксин в роли тимлида, инженер монтажа Сергей Паршаков, инженер звукозаписи Денис Шишкин и уже упомянутый программист из Грузии Бека Гозалишвили. О всех членах команды можно почитать в Instagram лаборатории.
Сначала Артём Плаксин написал потенциальному диктору и предложил поучаствовать в проекте. Артемий согласился.
Языковой модуль для русского языка у RHVoice Lab уже был. Он — база для создания любого голоса для синтезатора речи. Русскоязычный модуль был собран еще в самом начале существования проекта RHVoice, на нем Ольга Яковлева создала первый голос в RHVoice — Александр.
Языковой модуль – это то, на основе чего формируется голос, — некий свод правил, инструкция. Он определяет, как будет звучать та или иная графема, или буква, в определенной позиции. По сути, это просто много описаний в текстовых файлах, специального формата, в специальном синтаксисе.
Языковой модуль — результат сложной коллаборации программистов и лингвистов. Но его достаточно разработать один раз и создавать голоса уже на базе готового модуля. Естественно, языковая модель одного языка не подойдет для другого: на модели для русского языка не запишешь голос для украинского языка.
За более десятилетнее существование RHVoice были созданы языковые модули для американского английского, украинского, киргизского, грузинского, эсперанто. В последнем релизе добавился македонский язык.
Добавление новых языков – трудная задача. Помимо программистов, нужны языковеды, лингвисты, специализирующиеся на фонетике определенного языка. Поэтому новые языки добавляются не так часто, как хотелось бы, и не те, что обычно нужны людям. Одним из факторов создания языка является грант от какой-либо организации (например, United Nations Development Programme) или запрос от коммерческой компании. Так как разработка языкового модуля — трудоемкая задача, которая может занимать до полутора лет, добавлять язык без финансовой или грантовой поддержки непросто.
Что обычно делает диктор? Он должен записать от 600 до 2 500 предложений в зависимости от подобранной речевой базы. Это отдельные предложения, сформулированные так, чтобы содержать в себе все фонетическое богатство языка. В дальнейшем каждое отдельное предложение является единицей для тренировки.
Артемий Лебедев постепенно начал присылать фрагменты записей — всего он записал 1 160 предложений. Так сформировалась речевая база, пока что в сыром виде.
Время, которое уходит на запись речевой базы, зависит от диктора. Артемий Лебедев записал весь материал за 1 час 40 минут суммарно, а фактического текста вышло на 1,5 часа. То есть на монтаже лишними оказались лишь 10 минут. Обычно дикторы присылают от 1,5 до 3 часов готового материала. На запись у них уходит от 2 до 6 часов.
Далее запись в WAV-формате переходит в руки инженера монтажа — материал нужно порезать. В случае с Артемием были длинные куски по 10 минут, обычно в таких отрезках содержится порядка 200 предложений. Чтобы работать дальше, аудиофайлы нужно порезать на отдельные предложения так, чтобы один аудиофайл был равен одному предложению и длился 3-6 секунд. Количество аудиофайлов должно совпадать с количеством строк в текстово-речевой базе. Также на этом этапе убираются какие-то речевые огрехи.
Этап монтажа, в целом, не слишком длинный. Он занимает несколько суток, иногда неделю, если инженер монтажа занят. RHVoice Lab – некоммерческий проект, поэтому участники занимаются им в свободное время, когда есть время и силы.
После c очищенной базой начинает работать звукорежиссер, специалист RHVoice использует REAPER. Он корректирует амплитудно-частотные, а также спектральные характеристики записи, подбирает индивидуальное звучание диктора на основе его речевых особенностей. Это кропотливая работа: для создания качественного голоса каждый лишний звук должен быть убран, чтобы добиться стандартов дикторской речи без каких-либо шумов и посторонних звуков. Мастерство звукорежиссера важно, но также важно качество записи. Поэтому перед дикторами устанавливают достаточно высокую планку качества записи.
При записи аналогового звука в цифровой файл звук кодируется не слоями, а единым потоком. Это значит, что все звуки как бы вплетаются в полезный сигнал голоса диктора. Когда звукорежиссер вычитает какой-либо фрейм спектра из файла, страдает и полезный сигнал.
Допустим, диктор говорит слово «яблоко», а на букве Б нечаянно ударяет ногой по столу. Звук удара — это тоже звук, и если он находится прямо на какой-то букве, в синтезаторе речи эта модель будет распознаваться как буква с таким звуком.
После рендеринга аудиофайлы отправляются в комплекс программ, среди которых HTS (HMM-based speech synthesis system). Здесь звуки сопоставляются буквам.
Затем самая важная и сложная часть — тренировка речевой базы. Технический специалист извлекает фундаментальную частоту диктора и преобразовывает аудиоматериал в готовый голос.
На этом этапе специалист RHVoice Lab проверяет, как модель справляется с озвучиванием текста. Эта работа связана с тонкой настройкой. Важно подобрать идеальное звучание, чтобы не было коробочного звука или «деревянного» голоса, чтобы буквы читались четко. Если частоты подобраны некорректно, какие-то буквы — например, «п» и «т» — могут звучать одинаково.
Тренировка – это длительный процесс. Вкупе он может занимать от 6 до 15 часов в зависимости от размера речевой базы. Влияет и количество вычислительных мощностей: на старом сервере процесс мог занимать до 30 часов, но благодаря инфраструктуре от Selectel скорость увеличилась в разы.
Специалисты RHVoice Lab могут воссоздать голос не только ныне живущего человека. Так, команда сделала голос Юрий. Этот модуль воспроизводит текст с интонацией и характером актера и чтеца аудиокниг Юрия Николаевича Заборовского.
Получив согласие на создание голоса от вдовы, команда RHVoice Lab начала работу. Записать новую речевую было невозможно, поэтому они работали с тем, что было. В распоряжении энтузиастов было около 1 000 аудиокниг, которые озвучил легендарный чтец за последний 40 лет.
«Может показаться, что такое количество материала сильно облегчает нам работу, — говорит Артём Плаксин. — Но это совсем не так. Материал не подготовлен для обработки: диктор читал не однотонно, а экспрессивно, как художественную литературу. Нужно было вычленить наименее эмоциональные предложения, чтобы удовлетворить требования, которые мы предъявляем к записям от дикторов».
В итоге удалось вычленить 1 500 предложений для дальнейшей тренировки. Теперь Юрий есть в каталоге голосов RHVoice Lab. И все, кто «вырос» на голосе Юрия Заборовского, могут продолжать слушать тексты в его озвучке.
Это, конечно, уникальный случай. Голос удалось синтезировать только благодаря тому, что диктор оставил после себя много аудиофайлов со «слепками» своего голоса. Если речь идет о покойных певцах или актерах кино, задача невыполнима: слишком много лишних звуков будет на фоне.
Точно сказать, сколько человек пользуются в RHVoice, сложно. Суммарно голоса из каталога скачали около 15 000 раз. Но на эту цифру ориентироваться неправильно: многие голоса можно скачать напрямую из GitHub-репозитория RHVoice, какие-то распространяются по ссылкам через файлообменники.
Порог входа для использования инструмента невысокий: человеку достаточно уметь пользоваться скринридером. Подобные программы сейчас разработаны для всех популярных операционных систем: для MacOS, Android, Windows, даже Linux. С сайта RHVoice Lab можно скачать аддоны, которые достаточно легко установить в программы экранного доступа, — они представлены в форматах для NVDA и SAPI 5.
Сейчас RHVoice Lab работает на двух серверах. Один — «бывалый» сервер 2009 года — был подарен команде сервисом servero.ru. В нем четырехъядерный процессор, 32 Гб оперативной памяти и диск на 1 Тб. Этот сервер, где хранятся бэкапы тренировок и размещено рабочее облако проекта, поместили на colocation в один из дата-центров Selectel.
Второй сервер необходим для оперативной деятельности проекта. Раньше RHVoice Lab использовала мощности виртуальной машины с довольно скромными характеристиками: 4 ядра, 8 Гб RAM и SSD на 100 Гб. Пропускная способность — 100 Мбит/c.
Для разработчиков этот показатель был узким горлышком: только звукорежиссеру нужны были минимум 200 Мбит/с. И это без учета требований к синхронизации удаленно работающей команды. Конечно, канал не выдерживал, памяти не хватало, все было очень медленно. Маломощную «виртуалку» заменил сервер от Selectel, который компания предоставила RHVoice безвозмездно.
«Selectel предоставил нам выделенный сервер с процессором Intel Core i7-8700 (частота 3,2 ГГц, 6 ядер), 64 Гб оперативной памяти, два HDD-диска на 2 000 Гб. Один записанный голос может “отъесть” до 5 Гб оперативной памяти. Для оптимизации тренировки нового голоса мы запускаем сразу несколько его версий параллельно. Чтобы через день мы могли сравнить, что лучше сработало, а что хуже. На старом сервере мы себе такое позволить не могли — не хватало оперативки. Сейчас же мы можем хоть пять версий запускать одновременно», — делится руководитель RHVoice Lab.
По словам разработчиков, на старом сервере этап тренировки голоса занимал до 30 часов, на новом — около 10 часов. Конвертация исходных данных на первом этапе раньше занимала 55 минут, на новом сервере — 6 минут. Разница колоссальная.
«Сейчас мы не используем всю оперативную память, но мы намеренно взяли ресурсы с запасом. Так как наш план на будущее потребует больших вычислительных мощностей», — уточнил Артём.
9 голосовых баз данных, о которых вы должны знать
В ноябре 2017 года Mozilla представила первый выпуск своей модели расшифровки речи в текст с открытым исходным кодом. Точность этой модели приближается к человеческому восприятию звука. Что еще более важно, компания также выпустила вторую по величине в мире общедоступную базу голосовых данных под названием Common Voice — 20 000 человек по всему миру помогли этому проекту.
Mozilla начала работу над Common Voice в июле 2017 года, призывая добровольцев представить образцы своей речи или проверить автоматические расшифровки. К ноябрю накопилось около 400 000 записей, что составляет 500 часов речи.
«Это только первый релиз, дальше будет больше», — написал Шон Уайт в блоге и объяснил значимость Common Voice: «Одной из причин, почему на рынке так мало сервисов, является отсутствие данных. Стартапам, исследователям или тем, кто хочет работать с голосовыми технологиями, нужны высококачественные транскрибированные голосовые данные для совершенствования алгоритмов машинного обучения. Пока базы данных довольно ограниченные».

Действительно, разработчики жалуются на нехватку качественных данных для обучения искусственного интеллекта.
Конечно, Amazon и Google на протяжении многих лет собирали различные звуки и голоса. Некоторые из аудиоданных Google — общедоступные. Но Стивен Татеосян, директор по безопасному Интернету вещей и промышленным решениям в NXP Semiconductors, отметил, что этих данных недостаточно для разработки продукта производственного уровня. Или, возможно, они не самого высокого качества, недостаточно разнообразные.

В результате многие компании предпочитают создавать собственные базы данных. Некоторые компании используют данные из открытого доступа, чтобы дополнить свои разработки, другим компаниям для создания нишевого продукта достаточно общедоступных данных.
Итого, разработчикам пригодятся разные базы голосовых данных. Вот какие коллекции звуков и голосов (публичные и частные) стоит исследовать помимо Common Voice.
Google Audioset
Это расширяющаяся база из 635 классов звуковых событий и коллекция из 2 084 320 десятисекундных звуковых клипов из YouTube, отмеченных человеком. Эти 10-секундные сегменты видео доступны через поиск на основе метаданных, контекста и анализа контента.
Google пишет: «Результатом является набор данных беспрецедентного многообразия и размера, который, мы надеемся, существенно стимулирует разработку высокопроизводительных распознавателей звуковых событий. Выпуская AudioSet, мы надеемся решить задачу обнаружения звуковых событий, а также создать всесторонний словарь звуковых событий».
VoxCeleb
Масштабная база данных для идентификации ораторов. Содержит около 100 000 фраз от 1251 знаменитости, различных профессий, возрастов, с разными акцентами. Эти фразы взяты из видео на YouTube. «С помощью этой базы можно определить, какой звезде принадлежит голос», — утверждает VoxCeleb.

2000 HUB5 English Evaluation Transcripts
Эта база данных состоит из стенограмм 40 телефонных разговоров на английском языке. Разработана Консорциумом лингвистических данных с целью исследовать новые перспективные области в распознавании разговорной речи и преобразования разговорной речи в текст, разрабатывать передовые технологии, включающие эти идеи, и измерять производительность новых технологий.
Транскрибации 40 файлов исходных речевых данных представлены в формате .txt. Для составления базы использовались:
1) 20 телефонных разговоров, когда спикеры вели беседы на повседневные темы со случайными абонентами.
2) 20 телефонных разговоров без подготовленного заранее текста между носителями английского языка.
Callhome American English Speech
Еще одна разработка Консорциума лингвистических данных. В базе 120 получасовых телефонных разговоров между носителями английского языка — в основном между членами семьи или близкими друзьями. Все звонки исходили из Северной Америки. 90 из 120 звонков были сделаны за пределы континента, а остальные 30 звонков сделаны в Северной Америке.
LibriSpeech ASR Corpus
База данных LibriSpeech состоит из приблизительно 1000 часов записи английской речи — это прочитанные аудиокниги из проекта LibriVox. С помощью добровольцев этого проекта создано около 8000 аудиокниг для открытого доступа, большинство из которых на английском языке.

CHiME-5
Эта база данных посвящена проблеме распознавания разговорной речи в повседневной домашней обстановке. Речевой материал был получен путем записи двадцати отдельных вечеринок, которые проходят в реальных домах. Двухчасовая запись каждой вечеринки состояла из трех этапов: приготовление еды на кухне, обед в столовой, разговор после обеда в гостиной.
The TED-LIUM corpus
Материалы взяты на веб-сайте TED. Состоит из аудиозвонков и их транскрибаций. В базе 2351 аудио-разговор, 452 часов аудио и 2351 автоматических стенограмм в формате STM.
Free Spoken Digit Dataset
Голосовая база данных, состоящая из записей произносимых цифр. Записи обрезаются так, чтобы в начале и в конце была пауза.
Теперь вы можете говорить, используя чужой голос, с помощью Deep Learning
Дата публикации Jul 2, 2019

Синтез текста в речь (TTS) относится к искусственному преобразованию текста в аудио. Человек выполняет эту задачу, просто читая. Цель хорошей системы TTS – заставить компьютер делать это автоматически.
Один очень интересный выбор, который делается при создании такой системы, – это выборголосиспользовать для сгенерированного аудио. Должен ли это быть мужчина или женщина? Громкий голос или тихий?
Раньше это представляло ограничение при выполнении TTS с Deep Learning. Вам нужно собрать набор данных пар текст-речь. Набор ораторов, записавших эту речь, фиксирован – у вас не может быть неограниченных ораторов!
Поэтому, если вы хотите создать аудио своего голоса или чьего-либо другого, единственный способ сделать это – собрать новый набор данных.
ИИ исследования отGoogleпрозванныйКлонирование голоса позволяет компьютеру читать вслух, используялюбойголос.
Как работает голосовое клонирование
Понятно, что для того, чтобы компьютер мог читать вслух любым голосом, ему нужно как-то понимать две вещи: что он читает и как он читает.
Таким образом, исследователи Google разработали систему голосового клонирования, которая будет иметь 2 входа: текст, который мы хотим прочитать, и образец голоса, который мы хотим прочитать.
Например, если бы мы хотели, чтобы Бэтмен прочитал фразу «Я люблю пиццу», мы бы дали системе две вещи: текст, который говорит: «Я люблю пиццу», и короткий образец голоса Бэтмена, чтобы он знал, как Бэтмен должен звучать как , Результатом должен стать звук голоса Бэтмена со словами «Я люблю пиццу»!
С технической точки зрения система затем разбивается на 3 последовательных компонента:
(1) Учитывая небольшую звуковую выборку голоса, который мы хотим использовать, закодируйте волновую форму голоса в векторное представление с фиксированной размерностью
(2) Учитывая фрагмент текста, также закодируйте его в векторное представление. Объедините два вектора речи и текста и декодируйте их вспектрограмма
(3) Используйте вокодер, чтобы преобразовать спектрограмму в звуковую форму, которую мы можем слушать.

В статье три компонента обучаются независимо.
За последние несколько лет системы преобразования текста в речь привлекли большое внимание исследователей в сообществе глубокого обучения. И действительно, есть много предлагаемых решений для преобразования текста в речь, которые работают достаточно хорошо, основываясь на Deep Learning.
Важным моментом здесь является то, что система может взять «знания», которые кодировщик динамика узнает из голоса, и применить их к тексту.
После отдельного кодирования речь и тексткомбинированныйвобщее пространство для встраивания, а потомрасшифрованы вместесоздать окончательный выходной сигнал.
Код для клонирования голоса
Благодаря красоте мышления с открытым исходным кодом в сообществе искусственного интеллекта, существует публично доступная реализация этого клонирования голосаПрямо здесь! Вот как вы можете использовать это.
Сначала клонируйте хранилище.
Установите необходимые библиотеки. Обязательно используйте Python 3:
В файле README вы также найдете ссылки для скачиванияпредварительно обученные моделиа такжеНаборы данныхпопробовать некоторые образцы.
Наконец, вы можете открыть графический интерфейс, выполнив следующую команду:
Ниже представлена фотография того, как выглядит моя.

Как вы видите, я установил текст, который я хочу, чтобы компьютер читал справа: «Знаете ли вы, что Торонто Рэпторс – чемпионы по баскетболу? Баскетбол – отличный спорт ».
Вы можете нажать кнопки «Случайно» под каждым разделом, чтобы рандомизировать голосовой ввод, затем нажать «Загрузить», чтобы загрузить голосовой ввод в систему.
Datasetвыбирает набор данных, из которого вы будете выбирать образцы голоса,Ораторвыбирает человека, который говорит, ипроизнесениевыбирает фразу, произносимую голосом ввода. Чтобы услышать, как звучит входной голос, просто нажмите «Play».
После нажатия кнопки «Синтезировать и вокодировать» алгоритм запустится. Как только он закончится, вы увидите, что входной динамик читает ваш текст вслух.
Вы даже можете записать свой собственный голос в качестве входного сигнала, но нажав на кнопку «Записать один», с которой довольно весело поиграть!
Дальнейшее чтение
Если вы хотите узнать больше о том, как работает алгоритм, вы можете прочитатьОфициальная газета Google NIPS, Есть еще несколько результатов аудио образцаВот, Я бы очень клонировал репозиторий и попробовал эту удивительную систему!
Нравится учиться?
Следуй за мной пощебетгде я публикую все о новейших и лучших ИИ, технологиях и науке! Связаться со мной наLinkedInслишком!
Голосовой DeepFake, или Как работает технология клонирования голоса

Проблема синтеза речи из текста (Text-to-Speech, TTS) представляет собой одну из классических задач для искусственного интеллекта. Цель ИИ – автоматизировать процесс чтения текста, основываясь на наборах данных, содержащих пары «текст – аудиофайл».
Одной из важных проблем синтеза речи является задача создания образа голоса со всеми его характерными особенностями. Соответствующие наборы методик называют технологией клонирования голоса (англ. voice changing, voice cloning).
Решение указанной проблемы имеет множество практических приложений:
- адаптация голосов актёров при локализации фильмов
- озвучивание персонажей игр
- голосовые поздравления
- начитка аудиокниг, в том числе клонирование голосов родителей для сказок, прочитанных профессиональными дикторами
- создание аудио- и видеокурсов
- рекламные видеоролики и аудиореклама
- голоса ботов и умных устройств, персонализированных голосовых помощников
- синтез устной речи естественного звучания для немых людей, в том числе для людей, утративших возможность говорить из примеров их собственной речи
- адаптация устной речи под модель местного акцента
Очевидно, что подобные технологии могут применяться с преступными целями: мошенничество, телефонное хулиганство, компрометирование в результате совмещения с технологией DeepFake. Поэтому кроме методов клонирования голоса важно разрабатывать средства для предотвращения незаконного использования технологии.
Для обучения системы необходимо иметь большое количество сопоставленных аудиозаписей и текстов. В случае голосов знаменитостей можно прибегать к помощи записей публичных выступлений, интервью, результатам творческой деятельности и т. п. В качестве текстовых пар могут применяться стенограммы или тексты, полученные в результате коррекции автоматически распознанной речи.
Отличительной особенностью последних разработок является то, что для создания правдоподобного образа «голосовой мишени» достаточно всё меньших интервалов звучащей устной речи.
Современное состояние
В сфере создания инструментов для клонирования голоса работают множество команд, стремящихся к коммерциализации программных продуктов. По приведённым ниже ссылкам вы можете оценить текущее состояние технологии:
- Resemble.AI (предоставляется демоверсия программы).
- iSpeech (есть демо для 27 языков, включая русский).
- Lyrebird AI (можно загрузить демоверсию на 3 часа речи).
- Vera Voice, созданный компанией Screenlife Technologies Тимура Бекмамбетова и командой проекта «Робот Вера». Недавно команда показала пример адаптации голосов русских знаменитостей:
Другие компании стараются обойти стороной этический вопрос за счёт использования вместо клонирования голоса нейросетевых систем синтеза-смешения множества голосов. Таким коммерческим продуктом является, например, Yandex SpeechKit.
В связи с тем, что данная технология представляет конкурентный интерес для множества IT-компаний, проекты с открытым исходным кодом крайне редки. В этой статье мы остановимся на редком свободном проекте Real-Time Voice Cloning. Этот открытый репозиторий является результатом применения технологии переноса обучения SV2TTS, описанной в научной публикации (сэмплы, полученные в результате применения подхода).
Автор библиотеки с июня 2019 участвует в упомянутом выше коммерческом проекте Resemble.AI и уделяет репозиторию меньше времени, но ничто не мешает вам сделать собственный форк проекта.
Алгоритм клонирования голоса
Чтобы компьютер мог читать вслух текст, ему нужно понимать две вещи: что он читает и как это произнести. Поэтому в проекте Real-Time Voice Cloning система клонирования принимает два входных источника: текст, который необходимо озвучить, и образец голоса, которым этот текст должен быть прочитан.

С технической точки зрения система разбита на три компонента:
- Переданный аудиофайл с образцом речи, записанным в виде звуковой дорожки, преобразуется кодером речи (speaker encoder) в векторное представление фиксированной размерности.
- Переданный текст также кодируется в векторное представлении кодером текста (text encoder). Объединение речевого вектора и вектора текста декодируется в спектрограмму. Кодер текста, конкатенатор векторов и декодер (на схеме объединены синим цветом) представляют собой структуру синтезатора речи.
- Вокодер (vocoder, виртуальное устройство синтеза речи) преобразует спектрограмму в звуковую форму.
Модели трёх выделенных компонентов обучаются независимо друг от друга.
Где взять данные?
Объёмы информации, необходимой для качественного обучения системы клонирования, составляют десятки и сотни Гб. В рассматриваемой библиотеке для хранения датасетов служит одна общая директория. Все сценарии предварительной обработки данных выводят результаты в новый каталог SV2TTS , создаваемый в корневом каталоге датасетов. Внутри этой директории появится каталог для каждой модели: кодера, синтезатора и вокодера.
Для обучения кодера речи можно обратиться к следующим библиотекам:
- LibriSpeech (зеркало): набор данных train-other-500 (извлеките как LibriSpeech/train-other-500 ).
- VoxCeleb1: наборы данных Dev A–D, в том числе набор метаданных (извлеките как VoxCeleb1/wav и VoxCeleb1/vox1_meta.csv ).
- VoxCeleb2: наборы данных Dev A–H (извлеките как VoxCeleb2/dev ).
Для обучения синтезатор и вокодера:
- LibriSpeech: наборы данных train-clean-100 (зеркало) и train-clean-360 (зеркало) – извлеките как LibriSpeech/train-clean-100 and LibriSpeech/train-clean-360
- LibriSpeech alignments (только если у вас уже есть LibriSpeech): объедините структуру каталогов с загруженными вами наборами данных LibriSpeech
Официальным хостингом наиболее популярных наборов данных LibriSpeech служит openslr.org, который из-за популярности темы постоянно находится под существенной нагрузкой. Поэтому выше мы приложили ссылки на «зеркала» архивов.
Если вы решили с головой погрузиться в данную тему, обратите внимание на библиотеку Python для работы с аудиодатасетами audiodatasets:
Будьте осторожны: при установке библиотека загружает более 100 Гб данных трех наборов:
Перечислим также другие датасеты, которые не проверялись в рассматриваемой библиотеке, но применимы для обучения, в том числе корпуса русскоязычной устной речи:
- Корпус речи англоговорящих людей CSTR VCTK
- Набор данных M-AILABS: имеются примеры речи на русском, украинском, немецком, английском, испанском, итальянском, французском и польском языках
- Корпуса звучащей русской речи
- Мультимедийный корпус русского языка: преимущественно фрагменты кинофильмов с распознанным текстом
- Подборка различных речевых датасетов
Использование предобученных моделей
Имеется инструкция по переносу проекта с помощью Docker, здесь мы рассмотрим установку на локальной машине. Учтите, что наличие GPU является обязательным. Клонируем репозиторий:
В качестве языка программирования используется Python 3, автор рекомендует версию 3.7. В связи с тем, что репозиторий предполагает привлечение вполне конкретных версий библиотек, рекомендуем питонистам пускать в ход виртуальное окружение.
Переходим в папку и устанавливаем необходимые зависимости:
Также потребуется фреймворк глубокого обучения PyTorch (версия не ниже 1.0.1).
Далее необходимо загрузить предобученные модели (архив на Google drive, зеркало). Согласно с вышеописанной схеме загруженный архив содержит три директории для трех моделей. Их нужно слить вместе с соответствующими директориями корневого каталога библиотеки.
Проверить правильность конфигурации можно ещё до загрузки датасетов:
Если все тесты пройдены (вы увидите строку All tests passed ), можно двигаться дальше. Скрипт предложит указать пути к файлам примеров, но для работы удобнее обратиться кграфическому интерфейсу:
Если у вас уже загружены датасеты, то можно сразу указать путь к директории:
Чтобы просто поиграть с программой, достаточно наименьшего по объёму датасета LibriSpeech/train-clean-100 (см. выше).
Пример результата вызова интерфейса:
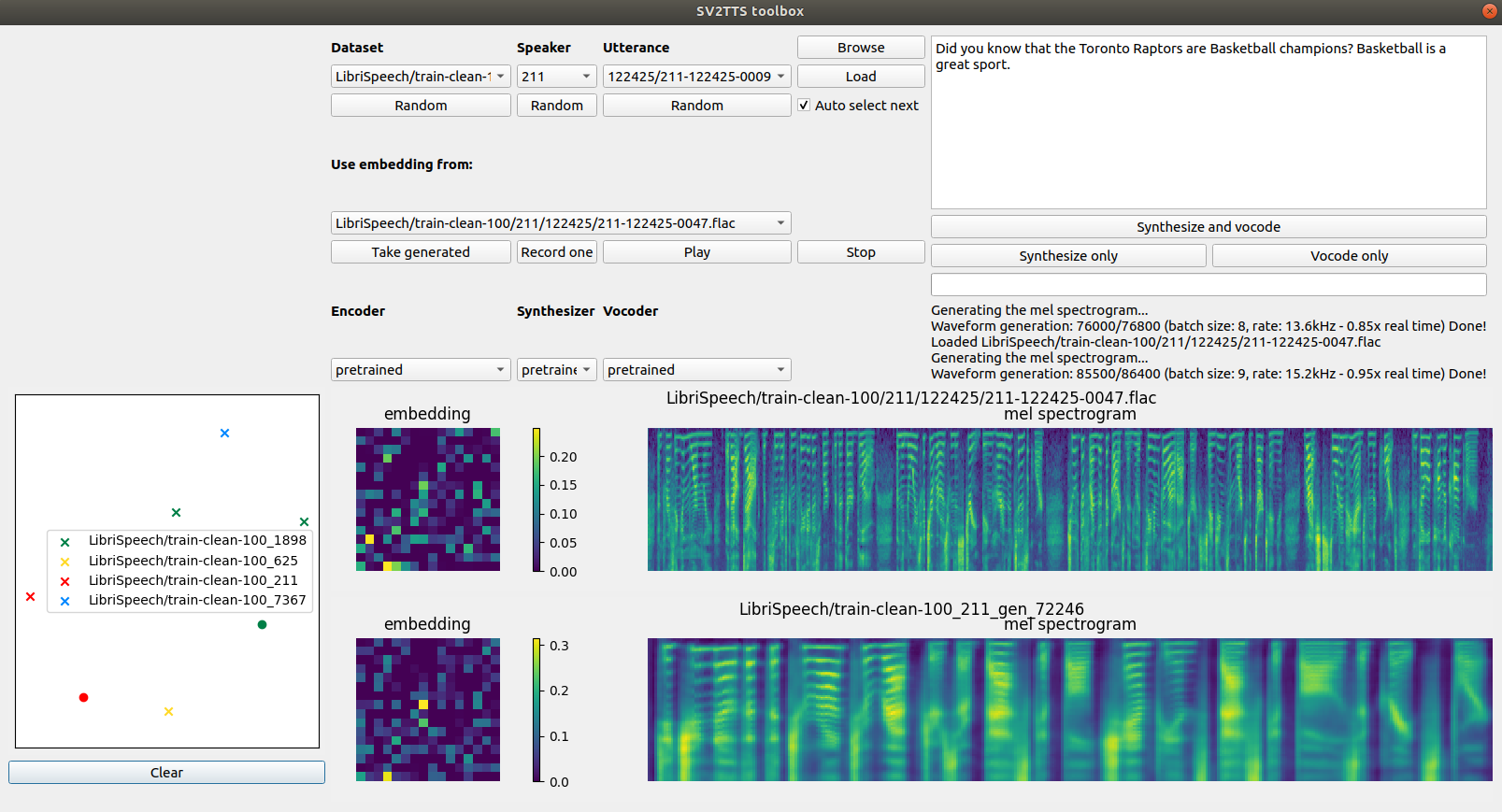
Для первой пробы вы можете нажать под каждым разделом кнопки Random , чтобы выбрать случайный аудиопример, затем Load , чтобы загрузить голосовой ввод в систему. Выпадающий список Dataset служит для выбора набора данных, Speaker – для выбора персоны, Utterance – для произносимой фразы. Чтобы услышать как звучит отрывок, просто нажмите Play . Для запуска алгоритма нажмите Synthesize and vocode . С помощью кнопки Record one можно записать свой собственный сэмпл.
Пример работы с интерфейсом без обучения нейросетей представлен в следующем видеоролике:
Процесс обучения
Вместо предобученных моделей можно также задействовать модели, обученные на других примерах. Процесс обучения происходит посредством последовательного запуска скриптов той же библиотеки. Для того, чтобы узнать дополнительную информацию о каждом из скриптов, при используйте запуске из командной строки добавляйте аргумент -h .
Начинаем с подготовки данных для обучения кодера:
Для обучения кодер использует окружение visdom . Инструменты окружения выглядят следующим образом:
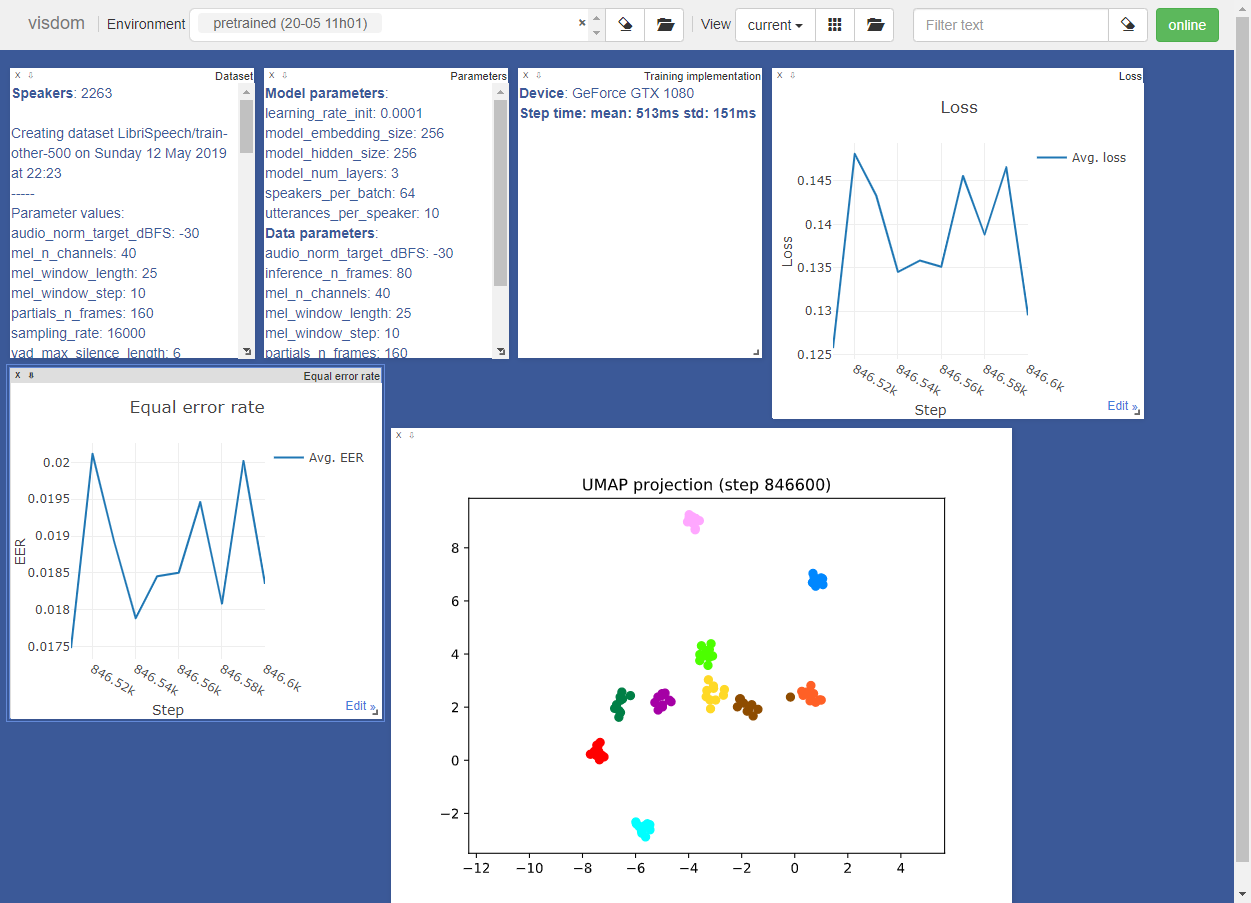
При необходимости вы можете отключить окружение с помощью аргумента –no_visdom .
Далее запускаем два скрипта, генерирующих данные для синтезатора. Начинаем с аудиофайлов:
Теперь вы можете обучить синтезатор:
Синтезатор будет выводить сгенерированные аудио и спектрограммы в каталог моделей. Используем синтезатор для генерации обучающих данных вокодера:
Наконец, обучаем вокодер:
Вокодер выводит сгенерированные аудиофайлы в директорию модели.
При возникновении вопросов относительно работы библиотеки мы также рекомендуем ознакомиться с диссертацией автора. Там же приведены ссылки на научные работы, посвящённые теме клонирования и изменения голоса.
Как настроить синтезатор речи Google на Android

В то время как Google фокусируется на Помощнике, владельцы Android не должны забывать о функции синтеза речи (TTS). Она преобразует текст из Ваших приложений для Android, но Вам может потребоваться изменить его, чтобы речь звучала так, как Вы этого хотите.
Изменение синтеза речи легко сделать из меню настроек специальных возможностей Android. Вы можете изменить скорость и тон выбранного Вами голоса, а также используемый голосовой движок.
Синтезатор речи Google — это голосовой движок по умолчанию, который предварительно установлен на большинстве устройств Android. Если на Вашем Android-устройстве он не установлен, Вы можете загрузить приложение Синтезатор речи Google из Google Play Store.
Изменение скорости речи и высоты тона
Android будет использовать настройки по умолчанию для Синтезатора речи Google, но Вам может потребоваться изменить скорость и высоту голоса, чтобы Вам было легче его понять.
Изменение скорости речи и высоты тона TTS требует, чтобы Вы попали в меню настроек специальных возможностей Google. Шаги для этого могут незначительно отличаться, в зависимости от Вашей версии Android и производителя Вашего устройства. В данной статье используется устройство Honor 8 lite, работающее на Android 8.0.
Чтобы открыть меню специальных возможностей Android, перейдите в меню «Настройки» Android. Это можно сделать, проведя пальцем вниз по экрану для доступа к панели уведомлений и нажав значок шестеренки в правом верхнем углу, или запустив приложение «Настройки» в своем списке приложений.

В меню «Настройки» нажмите «Управление», а оттуда «Специальные возможности».

Выберите «Синтез речи».

Отсюда Вы сможете изменить настройки преобразования текста в речь.
Изменение скорости речи
Скорость речи — это скорость, с которой будет говорить синтезатор речи. Если Ваш TTS движок слишком быстрый (или слишком медленный), речь может звучать искаженно или плохо для понимания.
Если Вы выполнили вышеуказанные действия, Вы должны увидеть слайдер под заголовком «Скорость речи» в меню «Синтез речи». Проведите пальцем вправо или влево, чтобы повысить или понизить скорость.
Нажмите кнопку «Прослушать пример», чтобы проверить новый уровень речи.

Изменение высоты тона
Если Вы чувствуете, что тон преобразованного текста в речь слишком высок (или низок), Вы можете изменить это, следуя тому же процессу, что и при изменении скорости речи.
Как и выше, в меню настроек «Синтез речи» отрегулируйте ползунок «Тон» в соответствии с желаемой высотой тона.
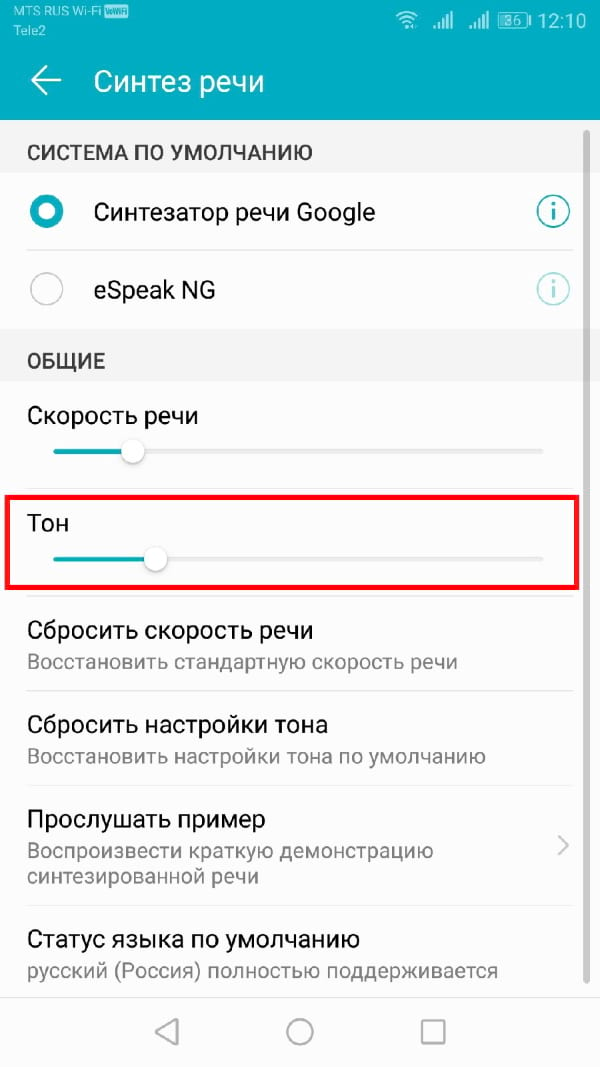
Когда Вы будете готовы, нажмите «Прослушать пример», чтобы попробовать новый вариант.
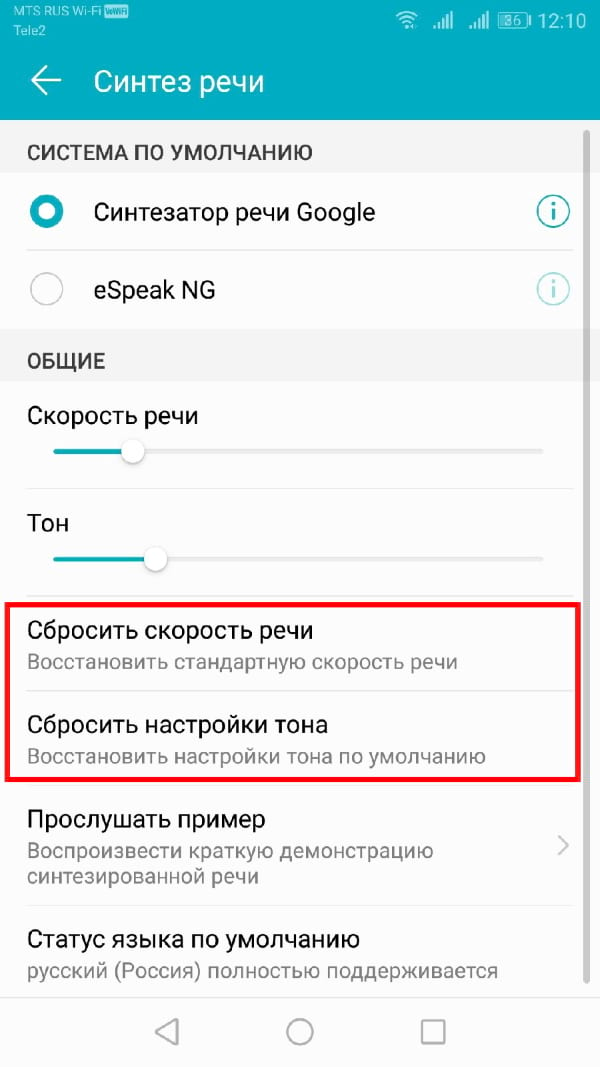
Продолжайте этот процесс, пока Вы не будете довольны настройками скорости речи и высоты тона, или нажмите «Сбросить скорость речи» и/или «Сбросить настройки тона», чтобы вернуться к настройкам TTS по умолчанию.
Выбор голоса синтезатора речи
Вы можете не только изменить тон и скорость своего речевого движка TTS, но и изменить голос. Некоторые языковые пакеты, включенные в стандартный движок Синтезатор речи Google, имеют разные голоса, которые звучат как мужской, так и женский.
Если Вы используете Синтезатор речи Google, нажмите кнопку «i» рядом названием.

В меню «Настройки» нажмите «Установка голосовых данных».
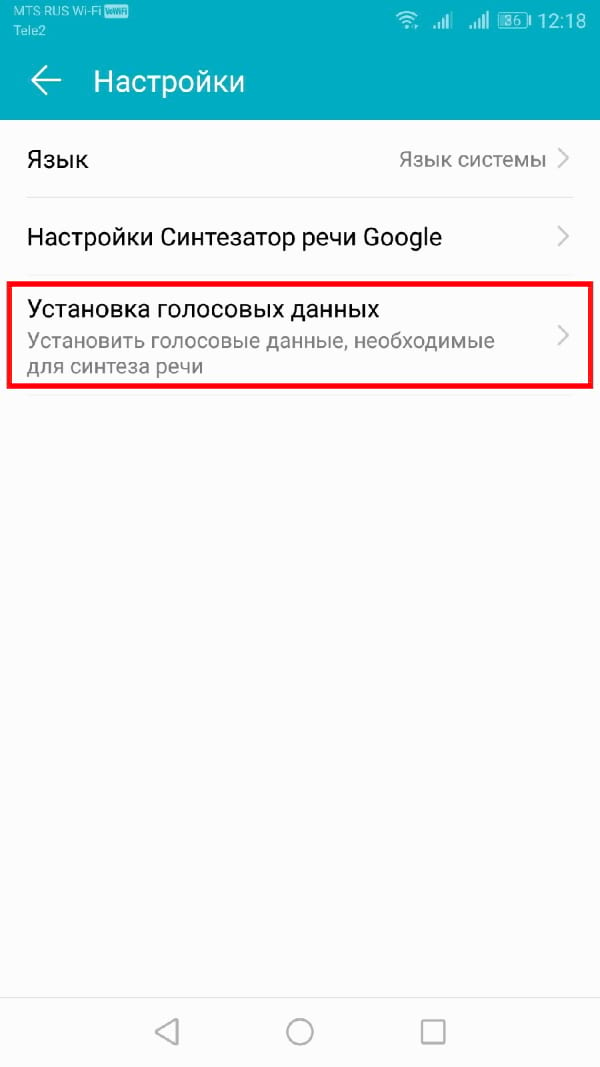
Нажмите на выбранный Вами язык.
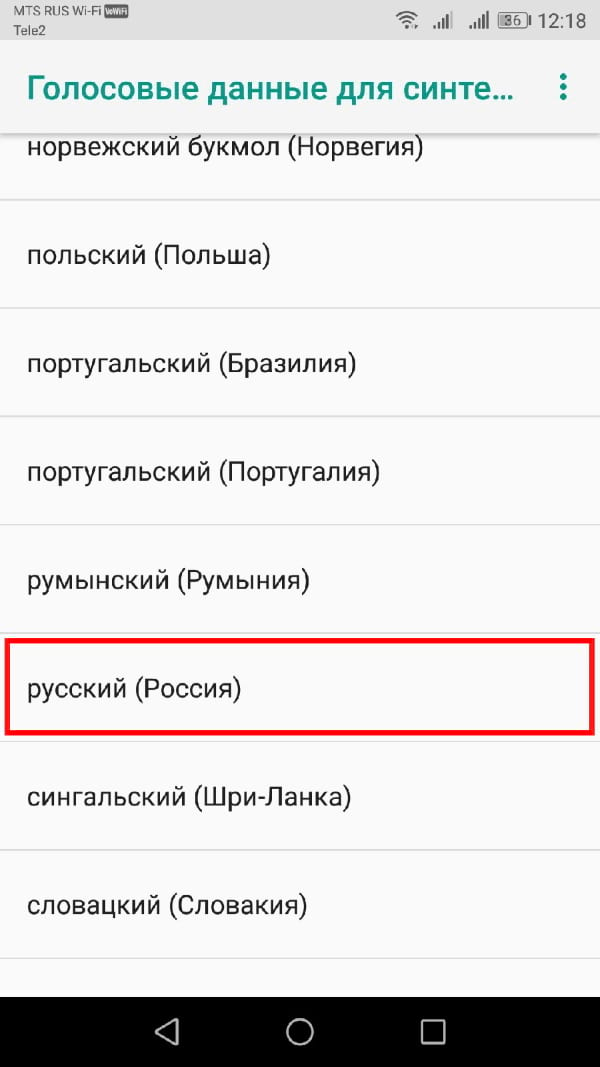
Вы увидите различные голоса, перечисленные и пронумерованные, начиная с «Голоса I». Нажмите на каждый, чтобы услышать, как он звучит. Вы должны убедиться, что на Вашем устройстве включен звук.
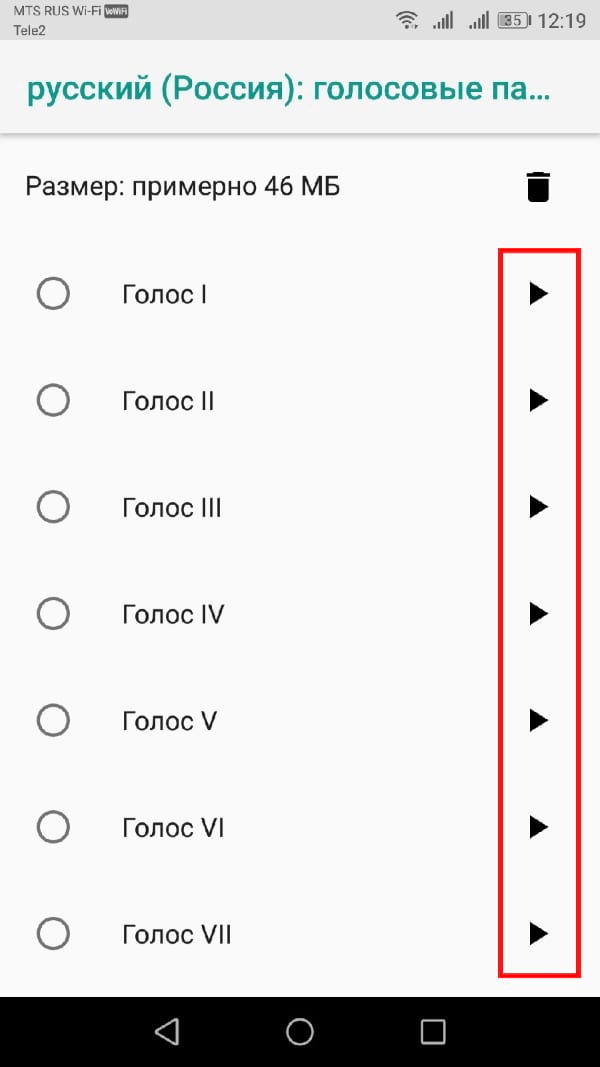
Выберите голос, который Вас устраивает в качестве Вашего окончательного выбора.
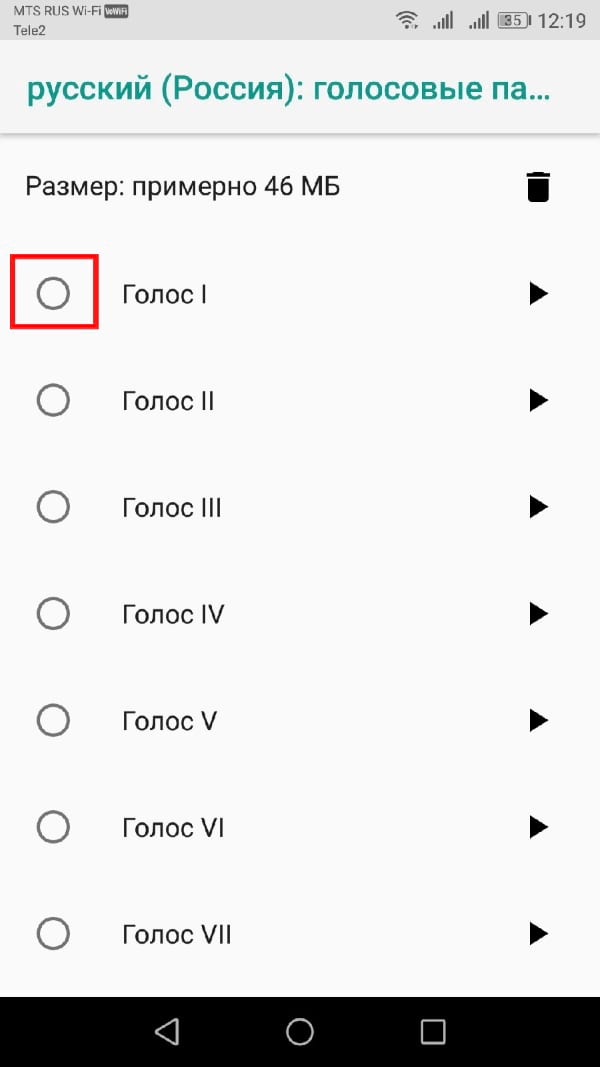
Ваш выбор будет автоматически сохранен, хотя, если Вы выбрали другой язык по умолчанию для Вашего устройства, Вам также придется изменить его.
Переключение языков
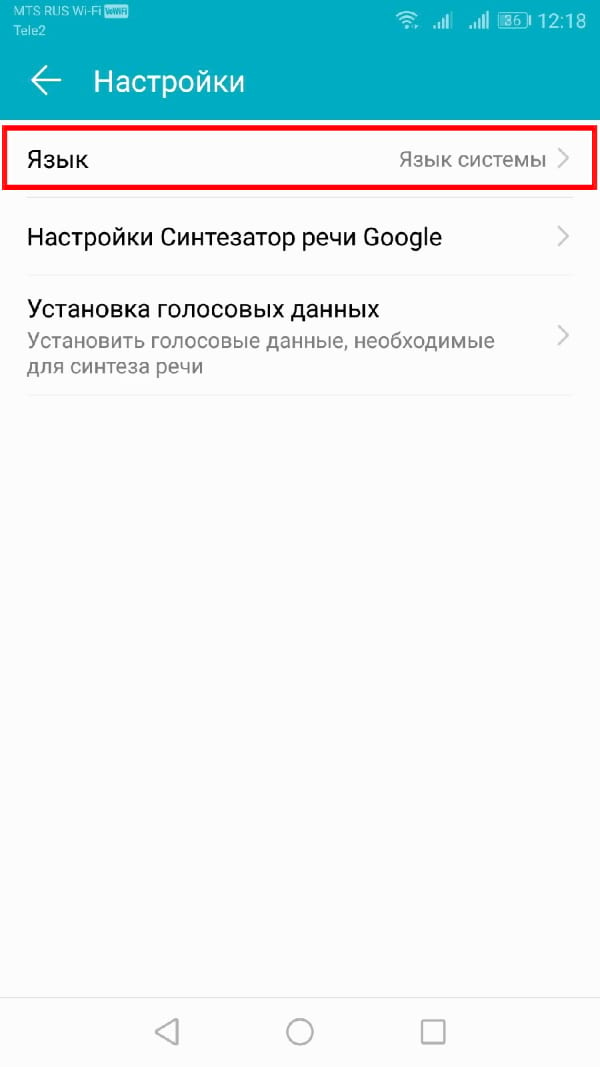
Если Вам нужно переключить язык, Вы можете легко сделать это из меню настроек Синтеза речи. Возможно, Вы захотите сделать это, если Вы выбрали язык в Вашем движке TTS, отличный от языка Вашей системы по умолчанию.
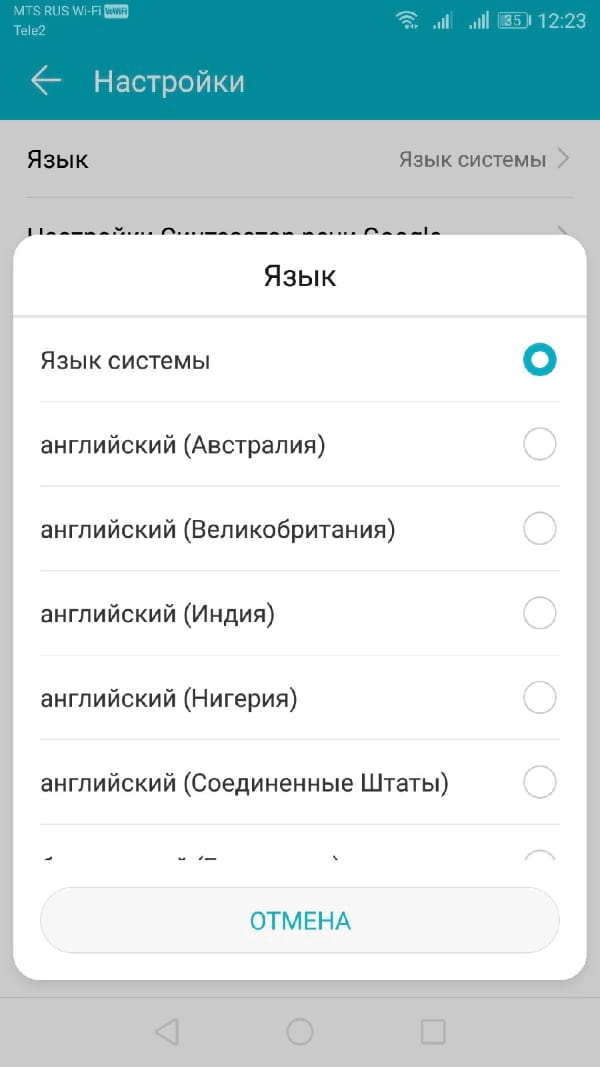
Вы должны увидеть опцию «Язык». Нажмите, чтобы открыть меню.
Выберите свой язык из списка, нажав на него.
Сторонние движки синтезатора речи
Если Синтезатор речи Google Вам не подходит, Вы можете установить альтернативные варианты.
Их можно установить из Google Play Store или установить вручную. Примеры движков TTS, которые Вы можете установить, включают Acapela и eSpeak TTS, хотя доступны и другие.
Обмани меня: как хакеры обходят системы биометрической защиты

В 2018 году в России был принят закон о создании Единой биометрической системы. Он разрешил кредитным организациям (а в перспективе и другим компаниям) использовать биометрию при удаленной идентификации клиентов. Звучит многообещающе, но только не с точки зрения информационной безопасности.
Согласно действующему ранее законодательству финансовые организации были обязаны подтверждать личность своих клиентов, требуя паспорт при личном присутствии в отделении. Это тормозило развитие финансовых сервисов в регионах, удаленных населенных пунктах или в случае, когда физическое присутствие потенциального клиента невозможно, например, по причине болезни. Удаленная идентификация с помощью биометрии должна была решить эту проблему.
«Идентификация Борна»
Существует три способа идентификации личности человека. Во-первых, мы можем убедиться, что он знает нечто секретное (например, кодовое слово или PIN), — это самый распространенный и недорогой в реализации механизм, который, однако, является и самым незащищенным. Узнать пароль несложно, редко кто следует правилам выбора надежных сочетаний символов. Вторым способом проверки является контроль владения некой неповторимой вещью (например, смарт-картой, ключом или штрих-кодом). Это более надежный и более дорогой способ аутентификации.
Наконец, третий способ — это проверить, что человек обладает какой-то уникальной физической, биологической, физиологической или поведенческой характеристикой (например, отпечатками пальцев или радужной оболочкой глаза). Именно этот метод сегодня набирает популярность, так как считается, что, помимо удобства для пользователя, он является и более защищенным. Но это не совсем так.
Если у пользователя украли пароль, это не смертельно, его можно заменить. Украденные карта или токен тоже подлежат восстановлению. А вот биометрический фактор уникален — ни при каких обстоятельствах вы не сможете изменить отпечатки пальцев, голос, глаза или расположение вен на руке. Это самые популярные методы биометрической идентификации, из которых в банках будут применяться пока только голос и геометрия лица. Среди других присущих человеку особенностей можно назвать почерк, в том числе и клавиатурный, запах, электроэнцефалограмму мозга и электрокардиограмму сердца, походку и даже геометрию ягодиц, которая, оказывается, тоже уникальна.
В принципе биометрия действительно решает многие классические проблемы. Традиционный вариант проверки личности клиента по кодовому слову и т.п. давно уже перестал хоть как-то защищать от мошенников. По данным исследования Opus Research A New Authentication Paradigm: Call Center Security without Compromising Customer Experience, 65% банковских клиентов не удовлетворены проверкой по паролю и кодовому слову при звонках в кол-центр. 49% клиентов считают, что проверка слишком долгая (от 40 до 90 секунд). 74% хотя бы раз не получили доступа к своим данным из-за того, что не прошли проверку и не смогли подтвердить свою личность стандартным способом. Может ли биометрия помочь в этих случаях?
Полагая, что биометрия сделает жизнь удобнее и безопаснее, мы начинаем ее активно внедрять, не взвесив все за и против. Что может угрожать биометрическим системам? Проблема в том, что «потерянные» голос или данные геометрии лица использовать снова будет невозможно. Разумеется, «потерять» их не так просто: они специальным образом преобразуются и затем хранятся в специальном хранилище.
В фантастических фильмах плохие парни отрезают пальцы, записывают голос, делают 3D-маски лица или муляжи ладони. Эти варианты атаки действительно существуют, но они направлены только на систему считывания биометрических данных. На самом деле векторов атак гораздо больше. Например, можно сломать сам считыватель, и что бы ему ни предъявляли, он будет выдавать ошибку. Можно вмешаться в работу системы верификации и поменять решение системы на нужное злоумышленникам. Можно взломать хранилище биометрических профилей и внести новые, а также подменить/уничтожить существующие данные по нужным людям. И это, пожалуй, самый опасный вариант для любой схемы биометрии.
Всего существует около полутора десятков способов взломать систему биометрической идентификации, и выбор наиболее удобных из них зависит от конкретных задач, стоящих перед хакерами. Если нужно дискредитировать всю систему, то атака будет направлена на хранилище биометрических профилей. Если нужно заставить систему принять «правильное» решение, то эффективнее атаковать систему верификации. Когда действия злоумышленников направлены на конкретного человека, то логичнее синтезировать его голос и видео. Существующие технологии уже позволяют, имея запись голоса или видео любого человека, синтезировать его речь или наложить его лицо на другую видеозапись.
Несовершенная система
Предлагаемая в России Единая биометрическая система (ЕБС) в своем роде уникальна: проектов такого масштаба в мире немного, и поэтому к их проектированию (особенно с точки зрения оценки актуальных угроз) подходить надо очень серьезно. Обнаруженные ошибки в такой системе надо будет устранять в масштабах всей страны. Апелляция к опыту хранения информации в системе биометрических паспортов не совсем корректна. Биометрические паспорта — это действительно защищенное хранилище, но к нему имеют доступ очень ограниченное число лиц. В основном это государственные органы: ФНС, ФМС, пограничная служба, МВД, ФСБ. Когда же мы говорим об удаленной идентификации, которую строят ЦБ и «Ростелеком», то к ней будет получать доступ гораздо большее количество организаций. По скромной оценке, их число будет измеряться несколькими сотнями, а то и тысячами, а значит, число точек проникновения в эту базу многократно увеличится.
При этом сами граждане подготовлены к переходу на биометрические технологии: они активно используют технологии распознавания лиц или отпечатков пальцев на мобильных устройствах при оплате в AppStore или Google Play. Более того, согласно отчету Cisco Customer Experience Research. Automotive Industry, проведенному Cisco в 10 странах, включая Россию, 60% граждан готовы предоставлять свои биометрические персональные данные, если это позволит усилить защиту их автомобиля, например, от угона или при дистанционном управлении отдельными функциями.
Сегодня при активном PR биометрических технологий о безопасности их применения в масштабах государства говорят мало. Возможно, это делается для того, чтобы не обозначить слабые зоны и не дать злоумышленникам подготовиться к атакам. Однако принцип «безопасность через незнание» в данном случае не работает. Необходимо широкое обсуждение механизмов защиты такой базы. Если ее взломают даже один раз, это подорвет доверие ко всей системе биометрической идентификации в России не только сейчас, но и в будущем.
Другая проблема связана с реализацией всей схемы удаленной идентификации. Во-первых, для того чтобы снять с клиента банка биометрический профиль, необходимо иметь достаточно мощное оборудование и специализированные комнаты. Механизм примерно тот же, что и при снятии биометрических данных при подготовке загранпаспортов. А поскольку в законе о внесении изменений в 115-ФЗ говорится не только о биометрии лица, но и о голосе, здесь потребуется еще и изолированное помещение, где бы отсутствовали любые посторонние звуки. А значит, первоначальная идентификация все равно потребует от пользователя явиться в определенное место, которое в регионах может находиться далеко от его места жительства. Но если образец записи будет создан в идеальных условиях, то при идентификации пользователя с помощью мобильного посторонние шумы или помехи некачественной связи могут привести к тому, что система не распознает его.
Разумеется, у биометрии есть безусловные преимущества, и при правильном ее использовании она действительно может сделать оказание различных услуг гораздо более удобным. Но при этом надо трезво оценивать все последствия для себя лично. Разумная осторожность никогда не бывает лишней.
