
Нейронная соната: как искусственный интеллект генерирует музыку

Об эксперте: Ольга Перепелкина, эксперт в области машинного обучения и нейросетей, преподаватель и автор курса Affective Computing в ВШЭ.
Творчество всегда считалось прерогативой человечества. И если в когнитивных задачах, таких как вычисления и обработка информации, мы уже признали превосходство искусственного интеллекта и активно пользуемся плодами автоматизации, то в таких «человеческих» видах деятельности как живопись, поэзия или композиторство алгоритмы нам уступают. И вообще, разве можно поставить на поток производство шедевров? Однако задачей автоматического создания картин, стихов и музыки ученые занимаются уже несколько десятилетий, и некоторые успехи определенно достигнуты.
Первая музыка, созданная с использованием компьютера, появилась в 1957 году в Bell Laboratories. Это была композиция длиной 17 секунд, которую ее автор Ньюман Гутман назвал The Silver Scale («Серебряная чешуя»):
В том же году The Illiac Suite стала первой партитурой, написанной компьютером. Она был названа в честь компьютера ILLIAC I университета штата Иллинойс в США. Это ранний пример алгоритмической композиции, основанной на вероятностном моделировании (цепях Маркова). В области синтеза звука знаменательным событием стал выпуск синтезатора DX 7 компанией Yamaha в 1983 году, использующего модель синтеза на основе частотной модуляции (FM).
Генерация музыки
Когда мы говорим о создании музыки при помощи компьютера, речь может идти как об ассистивной системе или компьютерной среде, помогающей музыкантам (композиторам, аранжировщикам, продюсерам), так и об автономной системе, нацеленной на создание оригинальной музыки. В обоих типах систем могут участвовать нейросетевые алгоритмы и глубокое обучение.
Мы также можем говорить о разных этапах создания музыки, где искусственный интеллект встраивается в процесс и помогает нам: сочинение, аранжировка, оркестровка и т.д. Когда человек сочиняет музыку, он редко создает новое произведение с нуля. Он повторно использует или адаптирует (сознательно или бессознательно) музыкальные элементы, которые слышал ранее, а также руководствуется принципами и рекомендациями из теории музыки. Так и компьютерный помощник может включаться на различных этапах создания произведения, чтобы инициировать, предлагать или дополнять композитора-человека.
Генерация нот
Традиционным подходом является создание музыки в символической форме. Результатом процесса генерации может быть музыкальная партитура, последовательность событий MIDI (распространенный стандарт цифровой звукозаписи), простая мелодия, последовательность аккордов, текстовое представление или какое-либо другое представление более высокого уровня. То есть искусственный интеллект создает символическую форму, по которой затем можно сыграть произведение.

Иными словами, физический процесс, посредством которого создается звук, упраздняется — вместо создания всего многообразия аудиосигнала, алгоритм выдает «инструкцию». Это резко сокращает объем информации, которую алгоритмы должны производить, что сводит проблему синтезирования к более решаемой и позволяет эффективно использовать простые модели машинного обучения.
Такой подход, например, позволил создать музыку в стиле Баха. Другой пример — нейросеть от OpenAI Musenet, которая появилась в апреле 2019 года. MuseNet может сочинять четырехминутные композиции на десяти инструментах и комбинировать стили «от Моцарта до Beatles». Эта нейросеть была обучена на огромном массиве MIDI-записей.
Генерация аудио
Но символический подход не позволяет создать нюансы человеческого голоса и различные характеристики тембра, динамики и выразительности музыкального произведения. Другой способ — это создавать музыку напрямую в виде аудиосигнала. Сложность этого подхода в том, что последовательность, которую мы в таком случае пытаемся создать — очень длинная. Например, для песни в несколько минут в хорошем студийном качестве это будет десятки миллионов значений.
В апреле 2020 года, компания OpenAI выпустила Jukebox, — нейросеть, которая генерирует музыку в различных жанрах. Она может сгенерировать даже элементарный голос, а также различные музыкальные инструменты. Jukebox создает аудиосигнал напрямую, минуя символьное представление. Такие музыкальные модели имеют гораздо большую емкость и сложность, чем их символьные аналоги, что подразумевает более высокие вычислительные требования для обучения модели.
Как творят нейросети?
Как же именно нейросети создают музыку? Общий принцип заключается в том, что нейросеть «смотрит» на огромное количество примеров и учится генерировать что-то похожее. В основе таких алгоритмов обычно лежат автокодировщики и генеративно-состязательные нейросети (Generative Adversarial Network, GAN).
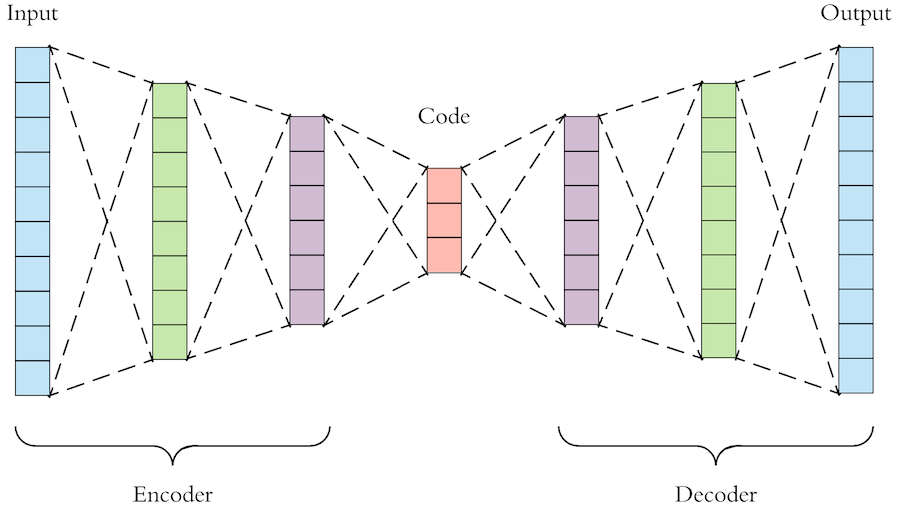
Автокодировщик — это нейросеть, которая учится представлять сложный и многомерный набор данных в «упрощенном» виде, а затем из этого упрощенного представления снова воссоздать исходные данные. То есть модель генерации музыки на основе автокодировщика сначала сжимает необработанный звук в пространство меньшей размерности, отбрасывая некоторые из несущественных для восприятия битов информации. Затем мы обучаем модель генерировать звук из этого сжатого пространства и повышать качество до исходного звукового пространства.
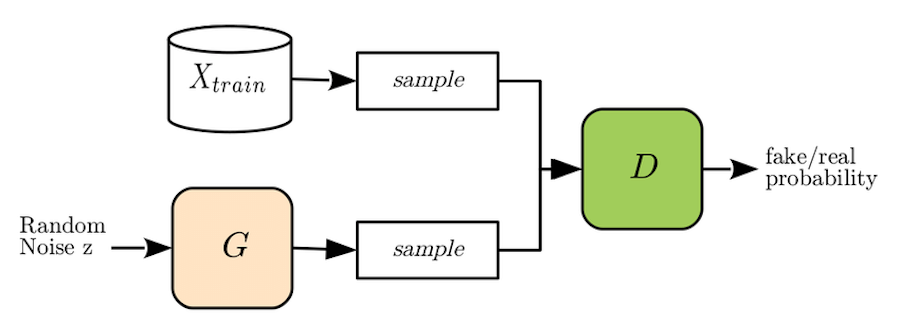
Генеративно-состязательную нейросеть метафорично можно представить как работу «фальшивомонетчика» и «следователя». Задача «фальшивомонетчика», или генеративой модели нейронной сети (generator, G), — создать из шума реалистичный экземпляр данных, например, изображение лица или, в нашем случае, музыкальную последовательность. «Следователь», или дискриминативная модель (discriminator, D) пытается отличить реальный экземпляр данных (настоящую фотографию лица или настоящую музыкальную мелодию) от «фальшивой», созданной генератором. И так, соревнуясь друг с другом, обе модели совершенствуют свои «навыки», в результате чего генеративная модель обучается создавать очень правдоподобные примеры данных.
Для обучения модели Jukebox использовал базу данных из 1,2 млн песен (600 тыс. из которых на английском языке), которая включала как сами композиции, так и тексты песен и метаданные — исполнителя, жанр и ключевые слова.
Музыкальный тест Тьюринга
Как понять, что музыкальное произведение, созданное машиной, действительно достойно нашего внимания? Для проверки работы систем искусственного интеллекта был придуман тест Тьюринга. Его идея заключается в том, что человек взаимодействует с компьютерной программой и с другим человеком. Мы задаем вопросы программе и человеку и пытаемся определить, с кем же мы разговариваем. Тест считается пройден программой, если мы не можем отличить программу от человека.
В области генерации музыки иногда используют «музыкальный тест Тьюринга». Так, например, был протестирован алгоритм DeepBach, который генерирует ноты в стиле Баха. Были опрошены более 1,2 тыс. людей (как эксперты, так и обычные люди), которые должны были отличить реального Баха от искусственного. И оказалось, что сделать это очень сложно — люди с трудом могут различать хоралы, сочиненные Бахом, и созданные DeepBach.

В области создания аудио успехи пока не столь впечатляющие. Несмотря на то, что Jukebox представляет собой смелый шаг вперед в плане качества музыки, длины аудио и способности настроиться на исполнителя или определенный жанр, различия между искусственной музыкой и произведениями, созданными людьми, все еще заметны. Так, в мелодиях от Jukebox хоть и есть традиционные аккорды и даже впечатляющие соло, мы не слышим крупные музыкальные структуры, такие как повторяющиеся припевы. Также в искусственных произведениях слышны шумы, связанные со способом работы моделей. Скорость генерации музыки также пока еще невысока — для полного рендеринга одной минуты звука с помощью Jukebox требуется около девяти часов, поэтому их пока нельзя использовать в интерактивных приложениях.
А как же лирика?
Хорошо, с музыкальными композициями разобрались, а как же тексты для песен? Может ли искусственный интеллект сочинять стихи? Да, и эта задача даже проще, чем написание мелодий, хотя и сложностей здесь тоже хватает — алгоритму нужно не только «придумать» осмысленный текст, но и учесть его ритмическую структуру.
В 2016 году разработчики “Яндекса” выпустили альбом «Нейронной обороны». В него вошли 13 песен в стиле «Гражданской обороны», тексты для которых сочинил искусственный интеллект. А годом позже вышел альбом «Neurona» с четырьмя песнями в стиле Nirvana, стихи для которых также были сгенерированы нейросетями.
Сейчас спою
Музыку мы создавать научились, стихи для нее писать — тоже, а как же быть с человеческим голосом? Могут ли нейросети петь вместо нас?
Генерация реалистичного человеческого голоса нужна не только для пения, но и во многих системах — от call-центров до личных голосовых помощников. Еще в 2016 году компания DeepMind выпустила алгоритм WaveNet, который создает очень реалистичный голос по заданному тексту (Text-To-Speech). Технология доступна для двух языков — английского и китайского.
В апреле 2020 года в ByteDance AI Lab (лаборатории компании, создавшей знаменитый TikTok) создали алгоритм ByteSing. Эта система на основе нейросетевых автокодировщиков позволяет генерировать очень реалистичное пение на китайском языке.
Большинство разработчиков современных алгоритмов генерации музыки, стихов и пения отмечают, что их системы являются ассистивными. Они не претендуют на полноценную замену человеческого творчества, а, напротив, призваны помочь человеческой музе. Человек не перестанет творить по мере развития алгоритмов и программ, но будет использовать их в своей деятельности. Очень вероятно, что в будущем великие шедевры будут созданы людьми и искусственным интеллектом совместно.
Искусственный интеллект будет генерировать музыку
Искусственная музыка: зачем нам
The Beatles, если есть ИИ
Искусственный интеллект с каждым годом занимает все более уверенные позиции в самой человеческой из жизненных сфер – в искусстве. Мир музыки не исключение. Нейросети пишут мелодии и ежедневно учатся делать это всё лучше. Примеров AI-творчества сотни. Так, еще в 2017 году вышел альбом Hello World, полностью созданный искусственным интеллектом в коллаборации с живыми музыкантами. Певица Тарин Саутерн вместе с AI-алгоритмом Amper записала песню Break Free, а нейросеть от проекта Flow Machines в соавторстве с композитором Бенуа Карре сочинила Daddy’s Car, стилистически идентичную музыке The Beatles.
Да чего уж, искусственный интеллект покусился даже на святое – классику. Например, нейросеть AIVA за 72 часа завершила пьесу чешского композитора Антонина Дворжака «Из мира будущего», которая оставалась неоконченной 115 лет, Flow Machines имитируют Баха, а нейросеть «Яндекса» вместе с композитором Кузьмой Бодровым сочинили пьесу, которую исполнил симфонический оркестр «Новая Россия» под управлением Юрия Башмета.
Однако пока искусственный интеллект творит не без помощи человека. Когда же нейросети начнут сочинять полноценную музыку самостоятельно? Rusbase пообщался с экспертами рынка и узнал, как творят нейросети, какую музыку точно заменит AI-музицирование и придется ли композиторам искать новую работу.

Описание и даже исходный код легко можно найти в интернете, воспользуясь которым любой толковый разработчик сможет написать нужную ему программу. Здесь нейросеть генерирует произведения в формате midi, разбитые на равные временные отрезки, в каждом из которых выделена основная нота. Похоже на то, как когда человек играет мелодию на фортепиано, тыкая пальцем в клавишу.
Для генерации таких midi алгоритм сначала пишет множество музыкальных произведений в сжатом цифровом виде, запоминает общие закономерности и в компактной форме записывает характерное для композиции уникальное свойство. Далее, применяя к полученным компактным представлениям знания о гармониях, нейросеть пытается восстановить произведение. С точки зрения человека, из 9/10 мелодий получается полная ерунда, которая звучит как какофония, а в 1/10 случаев – вполне приемлемая мелодия, с которой можно иметь дело. Но полноценной композицией она станет, только когда человек напишет к ней аранжировку.
Более интересный подход с точки зрения разработки, над которым сейчас бьются все – как сделать так, чтобы на выходе было не midi, а готовое музыкальное произведение. Сложность в том, что на отрезке в несколько секунд получается сгенерировать что-то звучащее как настоящая музыка, но добиться так называемой консистентности, когда на протяжении всего произведения чувствуется связующая идея, пока не получается.
Идеальный результат – произведение, которое нельзя отличить от написанного человеком. Задача открытая, но в целом понятно, как ее решать, и, думаю, в течение года мы увидим какой-то результат.




Начиная со второй половины XX века технологии активно пытаются сделать доступными массовому пользователю широкий выбор средств создания музыки. У любого подростка в ноутбуке может быть спрятан инструментарий симфонического оркестра, самые жирные хип-хоп биты и терабайтные библиотеки сэмплов для создания музыки в любых жанрах.
Все современные DAW (цифровая звуковая рабочая станция для создания и записи музыки) созданы так, что музыку можно собирать из составляющих как из кубиков: ты можешь не знать нот, не разбираться в теории, не уметь играть ни на одном музыкальном инструменте, но создашь из имеющихся компонентов простейшую композицию. Правда, скорее всего, звучать она будет посредственно, потому что не имеющий музыкального образования пользователь не сможет максимально использовать огромные возможности, которые сосредоточены в его компьютере.
Если на помощь приходит ИИ, то основная задача пользователя – грамотно сформулировать свои пожелания. Думаю, если вы скажете: хочу, чтоб было мелодично как у The Beatles, а по звуку как у Нины Кравиц, то, скорее всего, на выходе вас ожидает разочарование, так как результат будет звучать как фантастический уродец. Другими словами, для того, чтобы совместное с ИИ произведение было удачным, вы как хороший повар должны обладать знаниями о сочетаемости ингредиентов. А для этого и нужна музыкальная школа, где вас научат в том числе слушать, анализировать.
Как алгоритмы пишут свою музыку
Искусственный интеллект и нейросети нашли применение в десятках сфер, обеспечив мировому рынку объем почти в $40 млрд. Музыка не стала исключением. Сейчас это лишь зарождающийся сегмент с десятком небольших стартапов, но крупные корпорации уже проявляют интерес к технологиям генеративной музыки. Она призвана решить проблемы со стоимостью авторских прав и помочь композиторам и рынку музыкального стриминга, но пока и сама вызывает вопросы с точки зрения качества технологий и авторского права на конечный продукт.
В июле китайская интернет-корпорация ByteDance, владеющая мегапопулярным приложением с видеороликами TikTok и оценивающаяся, по разным данным, в $70–80 млрд, наняла всю команду небольшого британского стартапа Jukedeck и купила права на ее продукты. Вероятно, ByteDance планировала осуществить это незаметно, чтобы не привлекать внимание к технологии, которую она купила.
Jukedeck занимался созданием генерируемой искусственным интеллектом музыки, или музыки нейросетей. Такая технология, очевидно, будет очень полезной для TikTok, неотъемлемой частью которого является музыкальное сопровождение.
Крупных компаний, занимающихся только генерируемой (или генеративной) музыкой, на рынке пока не появилось, но есть более десятка небольших проектов, в том числе с российскими основателями. Один из таких — стартап Mubert с инвестициями фонда FunCubator. «В ближайшем будущем музыка, создаваемая алгоритмами здесь и сейчас, заменит стандартные плейлисты для сна, работы, отдыха и спорта, и мы увидим новый виток развития музыкальной индустрии»,— оптимистичен сооснователь Mubert Алексей Кочетков.
Он объясняет принцип работы технологии так: ИИ имитирует отдельные этапы создания музыки, например поиск настроения, аранжировку и сведение трека. В качестве «сырья», из которого ИИ генерирует музыку, у Mubert выступают купленные заранее сэмплы и звуки. В Mubert применяются скорее «ручные» алгоритмы, а не нейросети, и скоро такой подход окажется сильно позади, отмечает руководитель Лаборатории машинного интеллекта «Яндекса» Александр Крайнов. Среди других заметных проектов он называет AIVA, Creaited, Ecrett Music и Amper Music. Последний, к слову, с января прошлого года начал сотрудничать с еще одним китайским интернет-гигантом — компанией Tencent.
Первое и самое очевидное коммерческое использование генерируемой музыки — замена «стоковой» и фоновой музыки, то есть той, которую необходимо покупать для использования в цифровых продуктах или в офлайне. Чтобы включить чужую музыку в кафе, его владельцу необходимо заплатить крупную сумму в пользу лейблов, и генерируемая музыка призвана решить эту проблему.
Появление генеративной музыки может удешевить ее, сделать более доступной для бизнеса, рассуждает сооснователь и СЕО стримингового аудиосервиса для бизнеса Muzlab Виктор Христенко. «Сейчас музыкальный рынок поделен между крупными игроками. И появление работающей технологии позволит более мелким игрокам покупать музыку по более низкой цене»,— добавляет он. Впрочем, работать именно в этом сегменте, предоставляя возможности для создания композиций для офлайн-бизнеса, «никто не стремится», но у Mubert есть прототип и такого решения, отмечает управляющий партнер FunCubator Михаил Калашников.
Среди других перспективных направлений, где может использоваться генеративная музыка, господин Калашников называет рынок компьютерных игр и игрового стриминга. Весь мировой игровой рынок, по оценке аналитического агентства Newzoo, по итогам прошлого года превысил $152 млрд. «Проблема тоже реальна: в куче игр музыка довольно однообразна и надоедает с определенного момента. Этим направлением занимался, например, немецкий стартап Melodrive. Из известных кейсов: группа 65daysofstatic делала генеративный саундтрек для игры No Man`s Sky»,— отмечает управляющий партнер FunCubator.
«Скоро это может стать нишевым мейнстримом»
Весь мировой рынок искусственного интеллекта по итогам 2019 года мог достичь $35,8 млрд, прогнозировали в IDC. Однако оценить вклад генеративной музыки сложно: за прошедший год, кроме фактического приобретения Jukedeck со стороны ByteDance, других значимых сделок не произошло. По мнению Виктора Христенко, значимый самостоятельный рынок вокруг этой технологии и не появится — она найдет свое применение в других сегментах: «Музыка, созданная нейросетью, будет развиваться на уже существующем рынке и в рамках принятых моделей потребления».
Так, основатель Mubert Алексей Кочетков отталкивается от рынка музыкального стриминга, оцениваемого в $10–12 млрд с динамикой роста в 17,5% в год, поскольку именно в нем «растет влияние music-tech стартапов, и генерируемой музыки в частности». «Крупные компании интегрируют наши решения в свои приложения и сервисы. Голосовые ассистенты, приложения, “умные” колонки и провайдеры коммерческой музыки активно пилотируют нашу технологию, и скоро это может стать нишевым мейнстримом»,— говорит он.
Рынок фоновой музыки офлайн, например для кафе, торговых центров и аэропортов, где также находит применение генеративная музыка, можно оценить примерно в $1 млрд, считает Михаил Калашников: «Если с помощью фоновой музыки станет можно управлять продажами или загрузкой, емкость рынка значительно вырастет». Виктор Христенко признается, что Muzlab также экспериментировала с генеративной музыкой, однако результаты оказались неудовлетворительными. При этом компания в перспективе считает технологию интересной для своего бизнеса: «Наша бизнес-модель действительно отличается. Однако к моменту, когда появится работающая технология, у нас уже будут клиенты и мы сможем в любой момент запрыгнуть в этот поезд»,— рассчитывает он.
Свои возможности для генерации музыки с помощью нейросетей испытывал и «Яндекс» в совместном проекте с музыкантами. Но для компании это сейчас «творческие эксперименты без прагматических целей», утверждает Александр Крайнов. «Сложно сказать, к чему это (развитие генеративной музыки.— “Ъ” ) приведет. Может, это станет инструментом для профессиональных композиторов. Может, в определенных жанрах это полностью заменит композиторов»,— рассуждает он. Музыка, создаваемая нейросетью, уже сейчас может быть хорошим помощником для создания собственных композиций, уверен сооснователь Muzlab.
С точки зрения инвестиций сегмент выглядит интересным, отмечает основатель A.Partners Алексей Соловьев. «Развитие этого направления диктуется тремя трендами: трендом на персонализацию, на пользовательский контент и ужесточение копирайта. На их совокупности генеративная музыка играет очень эффективно»,— добавляет он.
Пока технологии создания музыки с применением искусственного интеллекта находятся на ранней стадии развития и многие ее аспекты неоднозначны. С точки зрения самостоятельного продукта такая музыка пока «в целом не очень хорошая и довольно примитивная», признает руководитель Лаборатории машинного интеллекта «Яндекса» Александр Крайнов. «В ней нет связанной истории. И не получается сложных произведений со своим “сюжетом”. Но это только пока»,— отмечает он, добавляя, что «все развивается очень быстро».
Ни в Spotify, ни в «Яндекс.Музыке» не удастся найти генеративную музыку в популярных плейлистах, соглашается Виктор Христенко. «Существующую генеративную музыку можно использовать для медитации или бега, но такая музыка, очевидно, нравится не всем»,— полагает глава Muzlab. Более того, пока нейросети плохо умеют создавать голос, «поэтому генеративную музыку с вокалом мы будем ждать еще больше», указывает господин Христенко.
С другой стороны, не решен и вопрос авторского права на такие музыкальные композиции. Спорные моменты могут возникать как при использовании в таких произведениях сэмплов других артистов, так и при «мимикрировании» под стиль конкретного исполнителя. «На данный момент вопрос авторских прав на музыку, созданную нейросетью, не изучен и в юридической практике нет прецедентов»,— утверждает Виктор Христенко. Обществу еще предстоит найти решение этого вопроса, подтверждает Александр Крайнов. «Мы верим в то, что победит подход, при котором такая музыка будет свободна от прав либо права на нее будут принадлежать тому, кто выбрал, обработал и сохранил лучшее из сгенерированного»,— говорит специалист, указывая на необходимость существования общедоступных объектов культуры.
Создаем музыку: когда простые решения превосходят по эффективности глубокое обучение
Представляю вашему вниманию перевод статьи «Создаем музыку: когда простые решения превосходят по эффективности глубокое обучение» о том, как искусственный интеллект применяется для создания музыки. Автор не использует нейронные сети для генерации музыки, а подходит к задаче, исходя из знания теории музыки, на основе мелодии и гармонии. Другой особенностью статьи является метод сравнения музыкальных произведений на основе матриц самоподобия. Такой подход, конечно, не является исчерпывающим, но он полезен как промежуточный шаг для генерации качественной музыки методами машинного обучения.

Использование искусственного интеллекта в творчестве сегодня стало встречаться все чаще и в развлекательных целях, и в коммерческих и уже перестало удивлять публику. С одной стороны — это инструменты смены стиля изображения типа Prizma. С другой — нейронная сеть, продукт работы которой был продан в виде картины на аукционе Christieʼs за 432,5 тысячи долларов. Нельзя не вспомнить нашего отечественного специалиста по генерации музыки с помощью машинного обучения Ивана Ямщикова, несколько лет назад представившего проект «Нейронная оборона» (подробнее можно прочитать здесь, а это интервью Ивана на Хабре). Другим хорошим примером использования нейронных сетей для генерации музыки может быть статья «Мечтают ли андроиды об электропанке? Как я учил нейронную сеть писать музыку» эксперта Artezio.
Помимо понимания теории машинного обучения, использование искусственного интеллекта для решения творческих задач предполагает также наличие экспертизы в доменной области искусства. Это делает проект на стыке двух областей особенно многогранным и интересным, но и уязвимым для критики с двух сторон, т. к. проект может попасть под перекрестный огонь замечаний и от искусствоведов, и от data scientist-ов.
Расширяя свой кругозор в рамках темы использования искусственного интеллекта в музыке, я встретил статью «Создаем музыку: когда простые решения превосходят по эффективности глубокое обучение», перевод которой хотел бы представить сообществу Хабра. Одним из достоинств этой статьи для меня стало то, что автор не использует нейронные сети как черный ящик, а подходит к задаче генерации музыки, исходя из знания теории музыки, на основе мелодии и гармонии. В представленной статье не используются ни рекуррентные нейронные сети (RNN, LSTM), ни генеративные состязательные сети (GAN), — все эти методы дают поразительные результаты (например, в статье «Мечтают ли андроиды об электропанке? Как я учил нейронную сеть писать музыку»), и мы активно их используем в решении наших задач в компании CleverData. Автор сделал упор на модели на основе марковских цепей, дающих возможность работать с вероятностями перехода от текущего состояния музыкального произведения в последующее. В используемых автором методах есть дополнительное достоинство: автору не пришлось жертвовать интерпретируемостью результата в угоду использования модного и популярного алгоритма.
Другой особенностью статьи, привлекшей мое внимание, стал интересный метод сравнения музыкальных произведений на основе матриц самоподобия. Если структуру песни можно представить в виде матрицы самоподобия, то появляется еще одна количественная мера сравнения песен.

Краткое содержание: как я столкнулся с проблемой, используя глубокое обучение для создания музыки, и как я её решил, придумав собственное решение.
Задача: как я столкнулся с проблемами при использовании техник глубокого обучения для создания поп-музыки.
Решение: как я создал собственную машину для создания музыки, которая могла бы конкурировать с глубоким обучением, но на основе более простых решений.
Оценка: как я создал оценочную метрику, которая могла бы математически доказать, что моя музыка «больше похожа на поп», чем та, что создана при помощи глубокого обучения.
Обобщение: как я нашёл способ применять своё решение к проблемам, не связанным с созданием музыки.
Вишенка на торте
Я создал простую вероятностную модель, генерирующую поп-музыку. Также, используя объективную метрику, я могу с уверенностью сказать, что музыка, созданная моей моделью, больше похожа на поп-музыку, чем та, что была создана с применением техник глубокого обучения. Как я это сделал? Частично, я достиг этого, сфокусировавшись на том, что для меня – суть поп-музыки: на статистической взаимосвязи между гармонией и мелодией.

Мелодия — это вокал, мотив. Гармония — это аккорды, последовательность аккордов. На рояле мелодия играется правой рукой, а гармония — левой.
Задача
Прежде чем углубиться в их отношения, позвольте мне сначала очертить проблему. Проект начался с моего желания попробовать создать музыку при помощи глубокого обучения – ИИ, как называют это непрофессионалы. Довольно быстро я пришёл к LSTM (долгая краткосрочная память, long short-term memory), одной из версий рекуррентной нейронной сети (RNN), очень популярной при генерировании текстов и создании музыки.
Но чем больше я вчитывался в предмет, тем больше я стал сомневаться в логике применения RNN и их вариаций для создания поп-музыки. Эта логика, казалось, основывалась на нескольких предположениях о внутренней структуре (поп) музыки, с которой я не мог полностью согласиться.
Одно конкретное предположение — это независимая связь между гармонией и мелодией (определение этих двух см. выше).
Например, рассмотрим публикацию Университета Торонто от 2017 года «Song from Pi: A Musically Plausible Network for Pop Music Generation» (Хан Чу и др.). В этой статье авторы явно «предполагают… аккорды не зависимы от мелодии» (курсив мой). Основываясь на этом предположении, авторы построили сложную многослойную RNN-модель. Для мелодии выделен отдельный слой, где создаются ноты (слой key, слой press), не зависимый от слоя аккордов (Chord Layer). Помимо независимости, эта конкретная модель предполагает, что гармония опирается на мелодию. Другими словами, гармония зависит от мелодии при генерации нот.
RNN-модель, предложенная Хан Чу. Каждый слой отвечает за отдельный аспект музыки.
Такой способ моделирования кажется мне очень странным, поскольку это совсем не похоже на то, как люди подходят к написанию поп-музыки. Будучи пианистом классической школы, я никогда не рассматривал сочинение мелодии без того, чтобы сначала обозначить гармонию. Гармония определяет и ограняет мелодию. Axis of Awesome в своём когда-то вирусном видео давно уже продемонстрировали правдивость этой идеи.
Это видео демонстрирует главное свойство западной поп-музыки: эта гармония, эти четыре аккорда сильно влияют на то, какой в итоге будет мелодия. Говоря языком Data Science, условная вероятность регулирует и определяет статистическую связь между гармонией и мелодией. Так происходит, потому что ноты мелодии, естественно, зависят от нот гармонии. Таким образом, можно утверждать, что ноты гармонии по своей сути указывают, какие мелодические ноты могут быть выбраны в конкретной песне.
Решение
Мне нравится находить оригинальные решения для сложных проблем. Поэтому я решил построить свою собственную модель, которая могла бы по-своему отражать богатую структуру музыкальных данных. Я начал с того, что сосредоточился на предопределенной вероятностной силе, регулирующей отношения между различными видами музыкальных нот. Например, выше я уже упоминал «вертикальные» отношения между гармонией и мелодией.
(Обработка) данных
В качестве данных я использовал 20 разнообразных западных поп-песен в midi формате (полный список песен можно найти здесь).
Используя библиотеку music21 python, я проанализировал midi-файлы при помощи цепи Маркова. Это позволило мне выделить статистические взаимоотношения между разными типами нот в моих входящих данных. В частности, я рассчитал вероятности перехода моих музыкальных нот. По сути, это означает, что наблюдая переход нот от одной к другой, мы можем вычислить вероятность того, что этот переход произойдет. (Более подробное объяснение ниже)
Midi: диджитал-версия песни
Сначала я извлек «вертикальные» вероятности перехода между нотами гармонии и нотами мелодии. Я также рассчитал все «горизонтальные» вероятности перехода между нотами мелодии в соответствии с набором данных. Я провел эту процедуру и для нот гармонии. Таблица ниже демонстрирует пример трех разных переходных матриц между различными типами нот в музыкальных данных.
Варианты перехода, варианты. Верхняя – между нотами гармонии и мелодии. Средняя – между нотами мелодии. Нижняя – между нотами гармонии.
Модель
Опираясь на эти три модели вероятностей, моя модель будет действовать следующим образом:
- Выбирает произвольную доступную ноту гармонии;
- Выбирает ноту мелодии, основываясь на ноте гармонии, используя первую вероятностную матрицу;
- Выбирает ноту мелодии, опираясь на предыдущую ноту мелодии, согласно второй матрице вероятности;
- Повторяет шаг 3, пока не достигнет определённого завершения;
- Выбирает новую ноту гармонии, опираясь на предыдущую ноту гармонии, используя третью матрицу вероятности;
- Повторяет шаги 1-4, пока не достигнет завершения.
Конкретный пример применения алгоритма:
- Программа выбрала гармоническую ноту ( F ).
- У этой ноты есть 4 варианта нот мелодии. Используя первую матрицу переходов, система выбирает ноту ( C ), учитывая высокую вероятность её использования (24,5%).
- Эта нота ( C ) переходит ко второй матрице перехода, останавливая выбор на ноте мелодии (A), основываясь на её частотности (88%).
- Шаг 3 будет повторяться, пока процесс не достигнет предустановленной точки завершения;
- Нота гармонии (F), обратившись к третьей вероятностной матрице, выберёт следующую гармоническую ноту. Это будет либо ( F ), либо ( C ), учитывая их схожесть.
- Шаги 1-4 будут повторяться, пока процесс не завершится.
Здесь можно послушать пример поп-музыки, созданной подобным образом:
Как искусственный интеллект сочиняет музыку




Пьеса «Из мира будущего» чешского композитора Антонина Дворжака оставалась незаконченной 115 лет. Искусственный интеллект AIVA завершил ее за 72 часа — и в позапрошлом году пьеса увидела свет в исполнении оркестра Пражской филармонии. Певица Граймс написала в соавторстве с нейросетью бесконечную колыбельную для своего ребенка по имени X Æ A-12. Зачем? Да чтобы не воспитывать его на устаревших детских песенках. А трек, состоящий из хрюканья коалы и криков кукабарры, принес своим создателям победу в первом «Евровидении» для ИИ. Рассказываем, на что еще способны нейросети в мире музыки, и предлагаем послушать самые интересные примеры.

Как вообще машина пишет музыку?
Прежде чем начать «сочинять», нейросеть учится. Программист « кормит» ее большим количеством музыкальных MIDI-дорожек, чтобы ИИ выявлял закономерности между звуками. Основываясь на этих самых закономерностях, компьютерный мозг генерирует что-то новое.

А какими способами?
Варианта два. Первый: машина « слушает» музыкальный фрагмент, а затем пытается воспроизвести его – так, чтобы было максимально похоже на оригинал. Второй: компьютер «слышит» одну ноту и пытается предсказать следующую, опираясь на свой «слушательский» опыт.

И что, из этого может получиться нормальный трек?
В среднем 9 из 10 мелодий, написанных нейросетью, звучат как какофония. Но оставшиеся 10% довольно приемлемы. Правда, полноценными композициями они становятся только после того, как обработкой займется человек. Без нас пока, к сожалению или к счастью, машине-композитору не обойтись.

Нейросеть feat. Скрябин
В 2017-м конференция Яндекса на тему применения новейших цифровых технологий неожиданно началась со звуков классической музыки. Камерный оркестр играл произведение в стиле композитора Александра Скрябина. Только вот создала ее нейросеть.
Чтобы машина написала музыку, программисты Яндекса Алексей Тихонов и Иван Ямщиков воспитывали ее не только на композициях Скрябина, но и на произведениях его великих предшественников — Моцарта, Брамса, Бетховена. В общей сложности нейросеть «проглотила» около 4 гигабайтов MIDI-файлов и примерно 600 часов музыки. После этого ликбеза машина выдала несколько треков, а композитор и эксперт по творчеству Скрябина Мария Чернова написала аранжировку. Вот что получилось.
В 2019 году нейросеть Яндекса в соавторстве с людьми выдала еще три трека. Композитор Кузьма Бодров выбрал несколько мелодических линий, сочиненных машиной, и на их основе написал 8-минутную пьесу для альта с оркестром. Это творение нейросети и Бодрова прозвучало на закрытии Зимнего международного фестиваля искусств в Сочи — причем в исполнении оркестра «Новая Россия» под управлением Юрия Башмета.
Техно-музыкант Никита Забелин тоже взял несколько музыкальных фрагментов, созданных нейросетью, и превратил их в эмбиент-трек. А вот группа «Комсомольск» не просто обогатила мелодию искусственного интеллекта аранжировкой, но и написала к ней текст — получилась песня под названием «Мы ищем человека».
Все эти дуэты людей и нейросетей вошли в альбом «Нечеловеческая музыка».
Новые релизы вместо Nirvana и Metallica
С музыкой понятно, но что со словами? Искусственный интеллект и рифмует неплохо. Пока группа Metallica уже несколько лет не может закончить новый альбом, блогер Funk Turkey «скормил» нейросети тексты рокеров о любви и смерти, и она предложила свою версию нового текста. Мелодию блогер придумал сам — получилась песня «Deliverance Rides». В комментариях кто-то сказал, что дал послушать трек отцу, и тот ответил: «Metallica так отлично не звучала уже давно».
На волне успеха Funk Turkey решил создать композицию в стиле Nirvana. Всю музыку и вокал он записал и свел на кухне, где, помимо плиты и чайника, были только гитара, плохой микрофон и программа Pro Tools. Текст снова написала нейросеть. Стихи получились слишком загадочными: «Я бы съел вашу коробку в форме сердца», «Эй, погоди! У меня тут комар!», «В соснах, где ты меня задушил». Но вопрос тут не к ИИ, а к текстам Курта Кобейна, из которых нейросеть повыбирала отдельные слова и речевые обороты.
Бесконечный концерт для басового соло
Если вы переслушали весь дэнс-панк или испанский джаз и соскучились по новым именам, ИИ может выступить в вашем любимом жанре. Например, в 2017 году машина создала альбом Coditany of Timeness на основе пластинки Diotima нью-йоркских блэк-металлистов Krallice. Получилось вполне реалистично.
Этот эксперимент был проведен в рамках проекта DADABOTS. Его основали два друга, которые познакомились на факультете компьютерных технологий Бостонского университета, — исследователь ИИ Си Джей Карр и саунд-продюсер Зак Зуковски. Возможностями нейросетей парни увлекались еще в студенческие годы и решили объединить этот интерес со своей страстью — хорошей музыкой.
После Coditany of Timeness ученая нейросеть DADABOTS написала еще несколько альбомов, «воспитанных» на треках таких экспериментальных рок-групп и металлистов, как Aepoch, Battles, Meshuggah. Искусственный интеллект так прокачался, что начал генерировать треки в прямом эфире ютуб-канала проекта. Прямо сейчас там можно послушать басовое соло, которое ИИ выдумывает на ходу — эфир начался 28 января и все еще продолжается !
Эмбиент на все случаи жизни
В 2019 году звукозаписывающая компания Warner Music впервые заключила контракт на создание музыки с помощью алгоритмов. Не с кем-нибудь, а с русскими парнями — основателями немецкого сервиса Endel.
Плодовитые алгоритмы Endel выпустили 20 альбомов с расслабляющими мелодиями. У каждого диска есть «погода» и настроение, только прочтите их названия: «Стрессовое облачное утро», «Расслабленный летний вечер», «Ясная ночь».
Стоит знать, что один из основателей Endel — Олег Ставицкий — музыке не учился, просто работал в журнале «Игромания» и часто писал статьи под эмбиент. Так ему было легче сосредоточиться. Только вот старые альбомы быстро надоедали, а найти классные новые было непросто. Тогда он задумал приложение, которое умело бы бесконечно генерировать эмбиент и помогало бы человеку сконцентрироваться, расслабиться или уснуть.
Система Endel берет за основу звуковые дорожки, которые пишет Дмитрий Евграфов, композитор и второй сооснователь приложения. И, помимо уже готовых плейлистов, Endel предлагает каждому пользователю музыку, которая автоматически пишется специально для него, собираясь из семплов и дорожек как конструктор. Система анализирует данные о человеке, например, измеряемую смарт-часами частоту пульса, а потом соотносит их с внешними факторами — временем суток, погодой за окном и местоположением. В результате ИИ пишет идеальный «саундтрек» для любого занятия. А е сли данные меняются, технология быстро на это реагирует и предлагает новое, более подходящее звуковое сопровождение — для работы, прогулки в парке, дневного сна или утреннего кофе.
Колыбельная для X Æ A-12
Пока основатель SpaceX Илон Маск планировал колонизировать Марс, его девушка — певица Граймс — записала для их ребенка X Æ A-12 колыбельную. Но не простую, а в паре с искусственным интеллектом — здесь ей на помощь пришли ребята из Endel.
Это все ради хайпа? Да нет. Девушка волновалась, что малышу X Æ A-12 не подойдут обычные детские песенки. Граймс, по собственному признанию, не хотела «портить ему знакомство с миром». А под Endel ей самой нравилось засыпать — вот и предложила им организовать для сына бесконечную цифровую колыбельную. Примеры мелодий Граймс записала самостоятельно. По словам певицы, для эксперимента она выбирала только те семплы, которые вызывали у малыша улыбку.
Песня коал, кукабарр и тасманских дьяволов
В Нидерландах в апреле 2020 года прошло первое «Евровидение» для нейросетей — Artificial Intelligence Song Contest . Участвовали команды из 13 стран, а оценивали их эксперты по машинному обучению. Победили австралийцы Uncanny Valley с композицией Beautiful The World. Песня, посвященная пожарам в Австралии, создана из звуков, которые издавали коалы, кукабарры и тасманские дьяволы.
Однако больше всего обсуждений в сети вызвала голландская команда Can AI Kick It с песней, а точнее, с революционным гимном, Abbus . В тексте, который написал искусственный интеллект, были такие строчки: «Посмотри на меня, революция. Это будет хорошо. Это будет хорошо, хорошо, хорошо. Мы хотим революции!»
К ак вообще на «Евровидении» могла появиться песня на эту тему? Виной тому был источник данных. Искусственный интеллект обучали не только на голландском фольклоре и лучших песнях « Евровидения», но и на текстах с онлайн-платформы Reddit, чтобы разнообразить язык. Так родилась песня с анархистским уклоном — нетипичный выбор для телевизионных конкурсов. Команда Can AI Kick It все же решила отправить жюри именно ее — чтобы показать, как непредсказуемо себя может повести ИИ в жизнерадостной попсовой среде.
Рейтинг лучших наушников для синхронного перевода иностранного языка
Наушники-переводчики входят в узкую категорию акустических устройств, предназначенных для быстрого перевода слов с одного языка на другой. Они подходят для путешественников или тех, кто хочет изучать иностранные языки. Рассказываем о том, что как выбирать наушники-переводчики, и какие модели заслуживают внимания в 2021 году.

- Что такое наушники для синхронного перевода текста
- Как выбрать синхронный переводчик речи
- ТОП-7: Лучших гарнитур для синхронного перевода – (Рейтинг 2021)
- Google Pixel Buds TWS
- Time Kettle WT2 Plus Earphones with translator
- Timekettle WT2 Plus
- Timekettle M2
- PeiKo World Smart Bluetooth
- Pilot Waverly Labs
- Timekettle WT2 Lite
- Вывод
Что такое наушники для синхронного перевода текста
На ежегодной выставке пользовательской электроники CES 2019 представили наушники, способные быстро обработать и перевести произнесенные слова на многие языки. Эта новинка произвела впечатление на тех, кто давно мечтал о возможности свободного общения с представителями разных языковых культур. Кроме того, эти устройства станут полезны для тех, кто часто выбирается за границу. С ними пропадет языковой барьер.
Также их часто используют представители правительства и, в том числе, МИД, для общения с международными коллегами.
Как выбрать синхронный переводчик речи
При выборе наушников с переводом иностранного языка учитывают ряд критериев:
- Количество поддерживаемых языков. В продаже есть наушники, поддерживающие от 10 до 90 языков. Если для пользователя важен какой-то один или два иностранных языка, то этот параметр роли не играет (главное, чтобы эти языки входили в число поддерживаемых). А для тех, кто часто путешествует или хочет изучать одновременно несколько языков этот критерий важен.
- Тип конструкции. По типу конструкции наушники-переводчики бывают внутриканальными и вкладышами. Первые вставляются непосредственно в слуховой канал, тем самым обеспечивая звукоизоляцию и улучшенную передачу звука. Вкладыши помещаются в ушную раковину. С ним пользователь будет лучше слышать все происходящее вокруг.
- Количество наушников. Наушник-переводчик может быть как один, так и иметь пару. Первый вариант дешевле, но он не обеспечивает должной звукоизоляции и не подходит для прослушивания музыки.
ТОП-7: Лучших гарнитур для синхронного перевода – (Рейтинг 2021)
| МЕСТО | МОДЕЛЬ | ОПИСАНИЕ | ЦЕНА |
| 1 | Timekettle WT2 Lite | Беспроводные наушники-переводчики с поддержкой 10 языков и 55 акцентов; | 14 990 руб. |
| 2 | Pilot Waverly Labs | Компактные и удобные в ношении наушники. Быстро переводят на 15 языков и 42 диалекта; | 33 990 руб. |
| 3 | PeiKo World Smart Bluetooth | Наушник переводчик с положительными отзывами; | 2 000 руб. |
| 4 | Timekettle M2 | Наушники для голосового двустороннего перевода, работающие с интернетом и без него; | 18 990 руб. |
| 5 | Timekettle WT2 plus | Эргономичная модель с шумоподавлением и поддержкой 36 языков; | 29 990 руб. |
| 6 | Time Kettle WT2 Plus Earphones with translator | Беспроводные наушники с шумоподавлением и продуманным корпусом. | 29 900 руб. |
| 7 | Google Pixel Buds TWS | Полностью беспроводные наушники-переводчики от Google. | 20 190 руб. |
7. Google Pixel Buds TWS
![]()
Google Pixel Buds TWS
Открывает рейтинг устройство для синхронного перевода речи Google Pixel Buds TWS. Наушники относятся к классу полностью беспроводных и имеют внутриканальную конструкцию. Они плотно сидят в ушах и не создают дискомфорт даже при долгом ношении.
Перевод происходит быстро и с минимальной задержкой на 40 языков. Для подключения используется Bluetooth 5.0, который гарантирует соединение на расстоянии до 10 метров.
Наушники-переводчики распознают иностранную речь и переводят ее на другие языки. Подобных моделей на рынке пока немного. Лучшие из них попали в наш рейтинг.

Рекомендации: 5 лучших микронаушников для сдачи экзаменов  , 5 лучших наушников Dacom
, 5 лучших наушников Dacom  , 6 лучших фирм-производителей наушников
, 6 лучших фирм-производителей наушников 
Лучшие наушники-переводчики
Устройства для перевода с одного языка на другой существовали и раньше, но не пользовались популярностью из-за большого количества смысловых ошибок. С появлением новых технологий ученым удалось усовершенствовать процесс.
В результате на рынок стали выходить современные наушники, способные правильно переводить речь в режиме реального времени на 40 языков мира. Они помогут преодолеть языковые преграды и обеспечивают комфорт при общении с иностранцами в путешествиях или на мероприятиях.
TimeKettle M2 Offline

Беспроводные наушники для офлайн-перевода
Многофункциональные вкладыши TimeKettle M2 исполняют качественный перевод на 40 языков мира. В местах, где нет подключения к сети интернет, доступен режим Offline.
Причины для покупки:
- стильный внешний вид;
- громкий и чистый звук;
- защита от влаги и пыли;
- быстрая зарядка;
- сенсорное управление.
TimeKettle M2 легко помещаются в ушных раковинах и не выпадают во время прогулок или спортивных занятий. Глянцевый пластик невосприимчив к поту и дождю, так как защищен от влаги по стандарту IPX4.
Беспроводную связь обеспечивает Bluetooth. Зарядный кейс гарантирует наушникам суммарно 30 часов автономной работы. Управление осуществляется сенсорным касанием ножки корпуса и через голосового помощника.
Устройство автоматически подключается к смартфону, быстро передает звук в режиме воспроизведения музыки и одним нажатием переключается на перевод. Доступны три режима: касание, спикер и слушатель. Активировав их, можно переводить разговор в реальном времени, слышать окружающих на своем родном языке, воспроизводить слова через динамик телефона.
Модель совместима со всеми смартфонами и удачно сочетает профессиональный перевод с повседневными функциями. В наборе с беспроводной гарнитурой идет кейс для зарядки, кабель и специальная карта с шестью языковыми пакетами для офлайн-перевода.
WT2 Plus

Для туристических поездок и деловых встреч
Незаменимые помощники для путешественников и людей, изучающих языки. Наушники не поддерживают телефонные звонки и прослушивание музыки, а предназначены исключительно для перевода.
Причины для покупки:
- лаконичный дизайн;
- огромный выбор языков;
- качественный перевод;
- беспроводное соединение.
Белые наушники изготовлены из ударопрочного пластика. Это современная Bluetooth-гарнитура с электронным переводчиком, распознающая 34 языка и 86 диалектов. Для работы используется технология искусственного интеллекта, переводящая иностранную речь с точностью 95%.
Пара наушников рассчитана на двух собеседников. В каждом вкладыше — микрофон с системой шумоподавления. Он фильтрует окружающие звуки, позволяя сосредоточиться на разговоре.
Чтобы приступить к общению, устанавливают приложение на смартфон, выбирают язык и режим. Предусмотрено три варианта перевода: «нажми и говори», спикер и автоопределение голоса для шумных мест.
Профессиональный переводчик WT2 Plus не боится пыли и влаги, поддерживает офлайн режим и рассчитан на 8 часов автономной работы. В комплекте идет зарядный кейс, кабель, два держателя для наушников и набор ушных вкладышей.
Pilot Waverly Labs

С функцией распознавания речи
Онлайн-переводчик Pilot от бренда Waverly Labs поддерживает 15 языков и делает общение людей из разных стран простым и понятным.
Причины для покупки:
- элегантный внешний вид;
- групповой перевод;
- функциональность;
- удобное приложение;
- портативность.
Беспроводные наушники-вкладыши имеют оригинальную форму, идеально подходящую для ушных раковин. Внутри — шумоподавляющие микрофоны, отсеивающие внешние звуки.
Каждый вкладыш можно настроить на перевод отдельного языка. Благодаря этому получается без проблем разговаривать с иностранными друзьями. Модель четко улавливает речь, поддерживает режимы прослушивания и устного перевода. Так же есть групповой перевод, когда любой желающий с наушником Pilot Waverly Labs может присоединиться к беседе.
Чтобы пользоваться наушниками, требуется установить на смартфон приложение Pilot Speech Translator. Программа осуществляет перевод и сопровождает его стенограммой на экране. Bluetooth-гарнитура работает и как обычные наушники для приема телефонных звонков или воспроизведения музыкальных композиций.
Bragi Dash Pro

Водонепроницаемые наушники с фитнес-тренером
Беспроводные наушники Bragi Dash Pro гарантируют качество связи, хороший звук и имеют много дополнительных функций, в том числе управление жестами и голосовые подсказки.
Причины для покупки:
- максимальная функциональность;
- стильный вид и миниатюрные габариты;
- надежная посадка;
- светодиодные индикаторы;
- алюминиевый футляр.
Bluetooth-гарнитура прочно фиксируется в ушах и обеспечивает комфорт при длительном ношении. Корпус защищен от влаги по стандарту IPX7, поэтому выдерживает тридцатиминутное погружение в воду на глубину 1 м.
Модель имеет 4 ГБ внутренней памяти, музыкальный плеер и фитнес-трекер. Спортивный тренер отслеживает частоту сердечных сокращений, считает пульс, шаги, количество сожженных калорий и дает полезные рекомендации.
Надев наушники, можно принимать звонки, просто кивнув головой, и общаться с собеседником, не доставая телефон из кармана. Бесплатное приложение Bragi App настраивает устройство под индивидуальные задачи владельца.
Важное преимущество аксессуара — мгновенный перевод речи с 40 языков, который осуществляет программа iTranslate. Для ее включения нужно, чтобы у обоих собеседников были наушники Bragi Dash Pro.
Google Pixel Buds
![]()
Умные наушники для перевода в режиме реального времени
Маленькие и незаметные Pixel Buds от компании Google надежно крепятся в ушах и предлагают отличное звучание в помещении и на улице. Кроме того, они дают быстрый доступ к сервису Google Translate.
Причины для покупки:
- необычный дизайн;
- качественная сборка;
- 24 часа автономной работы;
- голосовой ассистент;
- кейс для зарядки.
Pixel Buds, выполненные из пластика, имеют силиконовые вставки, удерживающие конструкцию в ушных раковинах. Внутри каждого наушника — мощный динамик и микрофон. Это дает возможность использовать вкладыши по отдельности без потери функциональности.
Внешняя сторона корпуса декорирована логотипом Google и является сенсорной. Подключение к смартфону происходит через Bluetooth. Для зарядки предусмотрен кейс с аккумулятором.
Беспроводная гарнитура совместима с техникой Android и iOS, но владельцы Android получают доступ к расширенным настройкам через приложение Pixel Buds. Легкое касание к правому наушнику включает Google Assistant. Личный голосовой помощник решает повседневные задачи, регулирует громкость, подбирает музыку, перематывает треки.
Еще одна ценная функция для пользователей — Google Translate. Встроенный переводчик на лету переводит зарубежные сайты, иностранную речь и транслирует перевод через наушники.
6 лучших наушников с хорошими басами 
Часто задаваемые вопросы
Как пользоваться наушниками-переводчиками?
Чтобы воспользоваться переводчиком, наушники синхронизируют со смартфоном, выбирают через приложение подходящий режим и начинают общение. Встроенная программа переводит произносимый текст, и он звучит в наушниках. Система быстро обрабатывает фразы. Задержка между приемом и выводом звука не превышает 3-5 секунд.
Как выбрать наушники-переводчики?
При покупке наушников с функцией перевода обращайте внимание на внеш технические характеристики. Чтобы прибор работал без сбоев, у него должна быть емкая батарея и возможность перевода в офлайн режиме. Убедитесь заранее, что модель поддерживает нужный язык, особенно если он относится к числу редких.
Чаще всего выпускают внутриканальные аксессуары, вставляющиеся в слуховое отверстие и обеспечивающие хорошую изоляцию и передачу звука. Каждый наушник имеет свою систему управления, микрофон и может настраиваться отдельно от другого. Это позволяет отдать один вкладыш собеседнику, который вас не понимает, и вступить в диалог.
Какие есть дополнительные функции?
Производители выпускают два вида наушников-переводчиков. В первых моделях нет дополнительных функций — они рассчитаны только на перевод. Вторые представляют собой многофункциональные устройства. С их помощью прослушивают музыку, отвечают на телефонные звонки, следят за показателями здоровья во время спортивных занятий, а не только переводят языки.
Для кого подходят наушники-переводчики?
Широкие возможности делают такую функциональную гарнитуру востребованной для разных людей. Предпринимателям и бизнесменам она нужна, чтобы проводить деловые встречи с иностранцами без присутствия профессионального переводчика. Туристы и путешественники берут ее в дорогу для общения с местными. Студенты благодаря ей облегчают обучение и лучше понимают живую речь.
Тематические материалы: 5 лучших игровых наушников с микрофоном  , 5 лучших наушников Bluedio
, 5 лучших наушников Bluedio  , 5 лучших наушников GAL
, 5 лучших наушников GAL  , 5 лучших наушников Xiaomi
, 5 лучших наушников Xiaomi  , 5 лучших наушников до 1000 рублей
, 5 лучших наушников до 1000 рублей  , 9 лучших вакуумных наушников
, 9 лучших вакуумных наушников  , Как пользоваться беспроводными Bluetooth наушниками
, Как пользоваться беспроводными Bluetooth наушниками  , Как правильно настроить эквалайзер (для наушников)
, Как правильно настроить эквалайзер (для наушников)  , На что влияет чувствительность наушников и какая лучше
, На что влияет чувствительность наушников и какая лучше 
