
Защиты от спама не будет
Счастье для всех и сразу
Одной из предпосылок того, что спам получил столь широкое распространение, послужила открытая архитектура почтового протокола SMTP. Так, например, для спамеров не представляет никакой сложности подделать заголовок письма «From:», что в совокупности с другими факторами делает отправителя мусора почти полностью анонимным.
С 2003 разрабатывались самые разные технологии аутентификации отправителя, которые по замыслу своих авторов должны были бы существенно помочь в деле выявления спамеров. Открытое сообщество ведет разработку расширения протокола SMTP – SPF, Sender Policy Framework. Microsoft пыталась в технологии SenderID объединить SPF со своей технологией CallerID, чтобы установить собственный стандарт в области почтовых протоколов – что ей не удалось, и рабочая группа по SenderID была распущена. Отметился на этом поле и Yahoo! со технологией аутентификации DomainKeys.
Сами по себе эти разработки не были задуманы как «убийцы» спама, однако прозрачность информации об отправителе вкупе с развитием антиспам-законодательства в США и Европе значительно затруднили бы жизнь спамерам, одновременно облегчив задачу фильтрации спамерского трафика. В итоге все забуксовало, когда стало ясно, что в одночасье внести изменения в глобальный почтовый протокол в масштабах всего интернета, на десятках и сотнях тысяч независимых серверов, не представляется возможным. Последний удар надеждам интернет-сообщества победить спам с помощью SPF и его собратьев нанес отчет Yahoo!, из которого следовало, что не более 3% входящих писем на Yahoo.Mail содержат SPF-метки, причем более 90% из них. являются спамом! Таким образом, стало ясно что никакой «серебряной пули» против спама не существует, а пророчество Гейтса образца 2003-го оказалось ошибочным.
Методы борьбы со спамом
Несмотря на столь апокалиптическую картину, снизить до приемлемого уровня количество мусора в собственном почтовом ящике все же можно. На рынке существует достаточное количество ПО антиспам-фильтрации – для домашних пользователей, компаний, интернет-провайдеров. Современные фильтры позволяют блокировать до 90-95% непрошенных массовых сообщений.
Все контентные фильтры используют в целом схожие методы определения спама в общем потоке почты – разбор технических атрибутов сообщения (заголовков, модификаций полей адресатов и отправителей, HTML-кода), поиск характерных для спама терминов, фраз и их сочетаний, а также проверенный сигнатурный метод, когда обнаруженная «свежая» рассылка блокируется на стороне пользователя еще до того, как она была окончательно разослана. Классическими примерами таких продуктов являются Symantec Brightmail Anti-Spam или Kaspersky Anti-Spam.
Другая группа антиспам-инструментов представлена «черными списками» спамерских IP-адресов – DNSBL (DNS-based Blackhole List). Особенно широко такие системы распространены у провайдеров. Используют чаще всего в совокупности с контентным фильтром. Как коммерческие сервисы, DNSBL представлены в лице Trend Micro RBL+, Spamhaus и других.
| Тренинг по теме “Защита корпоративной информации.” |
Еще один подход основан на анализе массовости того или иного сообщения в Сети. В России его используют для защиты пользователей “Яндекс.Почты”, а в США он широко используется в продуктах компании Commtouch.

На 100% отфильтровать спам сегодня невозможно. Для этого понадобилась бы система искусственного интеллекта, способная, как и человек, безошибочно реагировать на спам. Гораздо важнее отлова всех до единого спамерских сообщений безусловная сохранность обычной, не спамерской корреспонденции. За яркими лозунгами антиспам-вендоров, чьи декларируемые уровни детектирования достигают 99,99% можно не заметить опасности потерять важное письмо от клиента, руководителя, партнера. Поэтому основным приоритетом при выборе ПО должен быть минимальный процент false positives, ложных срабатываний спам-фильтра. У лучших представителей он не превышает нескольких писем (как правило, также рекламных, но не спамерских) на сотню тысяч сообщений.
Спам в конце тоннеля?
Участники прошедшей в Москве в декабре 3-й национальной конференции «Проблема спама и ее решения», констатировали, что решение проблемы спама в рамках отдельного провайдера или отдельной компании вполне достижимо. На рынке представлено достаточное количество средств противостояния электронному мусору и тем убыткам, – потерям времени, вирусным рассылкам, перегрузкам инфраструктуры – которые он несет за собой.
Однако на горизонте не наблюдается коренного решения проблемы спама в рамках Интернета в целом. Достигнут весьма неустойчивый баланс, когда спамеры существуют в условиях попадания лишь небольшой части их творений в цель, а вендоры – в перманентной борьбе за доли процента в уровне детектирования, каждый из которых дается все труднее. Какой-либо существенный технологический прорыв со стороны первых (тем более, что основные спамерские технологии не менялись уже почти 2 года) – и проблема может вновь принять ту остроту, которой она характеризовалась в 2003-м, когда старые средства уже не действовали и не было понятно, как защититься от напасти.
Тем более, что спамеры осваивают новые для себя каналы распространения – SMS и IM-пейджеры. И если SMS-спам теоретически может быть искоренен с помощью жесткого контроля со стороны сотовых операторов за своими шлюзами (что сейчас и происходит, например, в Китае, где SMS-спам приобрел масштабы стихийного бедствия), то пользователей ICQ, AOL и прочих пока попросту некому защитить, так как эти программы бесплатны, и их пользователи не готовы платить за антиспам-защиту. А значит, миллионы пользователей будут в раздражении давить клавишу Delete , отправляя очередную порцию спама в корзину.
Google анонсировал ИИ для борьбы со спамом

Искусственный интеллект предлагает «беспрецедентный потенциал для революции» в борьбе со спамом. Блокирует примерно 99% спама из результатов поиска.
Google объявила о внедрении новых инструментов искусственного интеллекта (AI), которые помогут бороться со спамом. Согласно внутренней оценке, ИИ способен блокировать 99% спама.
Подпишись на наш Телеграм и читай все статьи и новости первым!
Беспрецедентный потенциал борьбы со спамом
Есть несколько форм спама, с которыми Google борется на разных этапах взаимодействия Google с веб-страницами.
Google создал искусственный интеллект для борьбы со спамом, который, по словам Google, дает « беспрецедентный потенциал для революции » в борьбе со спамом.
Google специально сосредоточил свои алгоритмы борьбы со спамом на конфиденциальных запросах, которые были особенно важны для пользователей, связанных с такими важными темами, как поиск сайтов для медицинских тестов.
«Объединив наши глубокие знания о спаме с ИИ, в прошлом году мы смогли создать наш собственный ИИ для борьбы со спамом, который невероятно эффективен для выявления как известных, так и новых тенденций в области спама.
Например, мы сократили количество сайтов с автоматически созданным и извлеченным содержанием более чем на 80% по сравнению с тем, что было пару лет назад».
Спам на взломанных сайтах
Спамеры взламывают сайт и добавляют новые страницы со ссылками на другие сайты. Широко распространенный способ взлома сайтов, о котором предупреждает Google, называется взломом японских ключевых слов, потому что он добавляет страницы на японском языке. Он также может захватить вашу учетную запись в консоли поиска Google.
Компания Google утверждала, что поймала «большую часть» спама, созданного взломом сайтов. Технология искусственного интеллекта позволила Google более чем на 50% отловить его.
Три области, в которых Google блокирует спам
Google опубликовал диаграмму с указанием трех уровней, на которых он сталкивается со спамом, диагностирует его как спам и затем отклоняет.
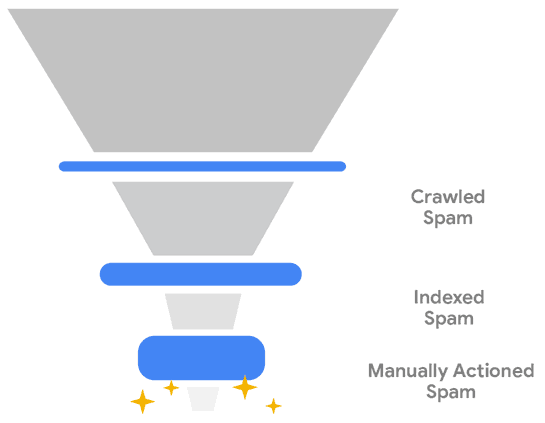
Иллюстрация: три области, где Google блокирует спам
Где Google блокирует спам
- Просканированный спам
- Индексированный спам
- Спам, обнаруженный вручную
Спам заблокирован до попадания в индекс
Сканер Google (GoogleBot) – это программное обеспечение, которое сканирует Интернет, чтобы найти веб-страницы, которые нужно включить в поисковый индекс Google, чтобы отобразить эти страницы в результатах поиска.
Сам сканер может улавливать спам по мере его обнаружения, чтобы спам не попал в индекс.
Спам, добавленный с помощью инструмента индексирования запросов Search Console, также перехватывается и удаляется, прежде чем он будет включен в поисковый индекс Google.
Спам в поисковом индексе заблокирован до ранжирования
Эти системы не улавливают весь спам, а часть спама попадает в поисковый индекс Google. Каждый раз, когда Google отвечает на поисковый запрос, Google будет сканировать веб-страницы, которые рассматриваются для ранжирования, чтобы найти больше спама.
Страницы со спамом, обнаруженные на этом уровне, используются для создания лучших алгоритмов борьбы со спамом на уровне сканирования Интернета.
Откуда берутся ручные действия
Google утверждает, что эти системы блокируют до пользователей 99% спама. То, что проходит, устраняется вручную.
«По нашим оценкам, эти автоматизированные системы помогают полностью исключить спам более 99% посещений из Поиска.
Что касается оставшегося крошечного процента, наши команды принимают меры вручную и используют полученные знания для дальнейшего улучшения наших автоматизированных систем».
Просмотр спама на сайте
Google добавил некачественные обзоры и сайты покупок в список сайтов, которые анализируются их инструментами ИИ. Google заявляет, что хочет вознаграждать за содержательный и полезный контент.
«… Мы хотели убедиться, что вы получаете наиболее полезную информацию для своей следующей покупки, поощряя контент, который содержит более подробные исследования и полезную информацию».
Борьба со спамом в Google, улучшенная с помощью искусственного интеллекта
Инструменты искусственного интеллекта были добавлены где-то в 2020 году. Неясно, насколько это могло повлиять на результаты поиска, но некоторые сайты, возможно, получили более высокий рейтинг из-за удаления спам-сайтов, которые ранее имели высокий рейтинг.
Применение искусственного интеллекта для фильтрации массовых email-рассылок
Что такое искусственный интеллект?
Хороший вопрос. Искусственный интеллект можно определить как научную дисциплину, которая занимается моделированием разумного поведения. Это определение имеет один существенный недостаток – понятие интеллекта трудно объяснить. Вряд ли кто-то сможет дать интеллекту довольно конкретное определение для оценки предположительно разумной компьютерной программы и одновременно отражающее жизнеспособность и сложность человеческого разума.
Одно из наиболее разработанных (и теоретически, и практически) направлений искусственного интеллекта – машинное обучение. Это класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а способность к обучению в процессе применения решений множества сходных задач. Рассмотрим на примере спам-фильтров. Современные спам-фильтры, котрыми пользуются в Google, Yahoo, Ukr.net и другие почтовики – это сложные системы, но основная идея в их разработке проста. Надо сначала научить компьютер классифицировать письма как спам или не спам, а потом применять разработанный фильтр на практике.

Основную идею обучения тоже несложно понять. Сначала письма формализуют по каким-то параметрам (наличие/ отсутствие тех или иных слов в письме, тема письма и т.п.), причем для каждого конкретного письма известно является ли оно спамом или нет. Потом компьютер обучают разбивать письма по этим параметрам на две категории. Чем тщательнее выбираются параметры по которым производится обучение, тем лучше будет результат и точнее будет работать классификатор. Опять же точность классификации напрямую зависит от объема данных на которых производят обучение – чем больше примеров, тем точнее правила классфикации вырабатывает компьютер.
Есть много разнообразных алгоритмов, которые можно применить для обучения – это тоже влияет на результат. Чтобы практически собрать все воедино и заставить это работать нужно владеть специальными навыками и опытом, но основные идеи может понять каждый.
Допустим, мы разработали алгоритм классификации писем и обучили его на релевантном количестве примеров. Как же компьютер определяет является спамом новое письмо, которое не было использовано для обучения? Оказывается, все что он делает в этом случае – определяет вероятность того, что письмо есть спамом или нет. Чем выше вероятность, тем более уверенны мы можем быть в результате. Но чтобы отнести письмо к той или иной категории нужно выбрать определенный вероятностный барьер, выше которого мы будем определять письма как спам. Выбор этого барьера – непростая задача. Она решается для каждого конкретного алгоритма классификации индивидуально учитывая особенности данных, постановки задачи, ожидаемого результата и т.п.
Следует помнить, как хорош алгоритм не был бы, он все равно будет допускать некоторые погрешности в классификации. Определение точности алгоритма – обязательная задача, которая должна быть решена в ходе разработки любой системы искусственного интеллекта.
Какие фильтры мы используем в eSputnik Intelligence?
Теперь, когда мы разобрались с понятиями машинного обучения и классификатора, можно перейти к описанию алгоритмов классификации пользователей, которые мы применяем в системе eSputnik Intelligence для фильтрации массовых email-рассылок.
Для определения отправлять конкретному пользователю письмо или нет, мы используем всю предыдущую историю действий пользователя. При этом мы разработали несколько различных алгоритмов, базируясь на идеях широко известного RFM-анализа. Наши алгоритмы работают на таких наборах метрик:
- Общие количественные показатели включают: общее число полученных пользователем писем в рамках данной рассылки, общее время жизни клиента и т.п.
- Частота открытия писем. Чтобы учесть динамику поведения пользователя в его клиентской истории, выделяем несколько различных частот, которые учитывают как усредненные показатели так и поведенченские паттерны в разные периоды времени. Например, мы используем такие показатели:
- общая частота открытия писем пользователем в рамках данной рассылки
- частота открытия за последние N полученных писем (например 30 и 10)
- частота прочтения писем по будням и по выходным и т.п.
- Последние активные действия клиента. Сюда время до последнего (релевантного) открытия, совершал ли открытия и переходы пользователь за последние несколько дней (например, последнюю неделю) и т.п.
Базируясь на таких параметрах удается построить довольно эффективные алгоритмы классификации активности пользователей и предсказать откроет или нет пользователь данное конкретное письмо перед его рассылкой. Особенности массовых рассылок таковы, что показатели прочтения писем обычно не очень высоки. Всегда намного больше тех пользователей, которые не прочтут письмо, по сравнению с теми, которые таки прочтут, и, тем более, перейдут по ссылке. Поэтому гораздо проще и эффективнее выделять группу пользователей, которые с большой вероятностью не прочтут письмо. Здесь стоит определиться, что мы понимаем под “большой вероятностью”.
Эффективный email-маркетинг с eSputnik
От выбора вероятностного барьера зависит как размер группы пользователей, которых алгоритм будет рекомендовать исключить из конкретной рассылки и применить к ним реактивацию, так величина допускаемой при этом ошибки. Под ошибкой мы будем понимать ситуацию, когда рекомендуется не отправлять письмо пользователю из-за малой вероятности его открытия, но тем не менее пользователь его открывает. Вообще, в математической статистике принято использовать 95% и 99% вероятностные барьеры. Мы посмотрим как будут изменятся результаты применения разработанных нами фильтров от выбора барьера в диапазоне от 95% до 99%. Когда мы говорим, что вероятностный барьер равен 98%, то имеем ввиду, что будем фильтровать всех пользователей, для которых вероятность непрочтения конкретного письма в рамках данной рассылки превышает 98%.
Какие результаты мы получаем?
Мы постараемся ответить на три основных вопроса:
- Какую ошибку допускают разработанные нами фильтры?
- Какую часть данных можно дополнительно отфильтровать по сравнению с традиционно используемым правилом “90 дней”?
- Какую часть потенциальных открытий мы все же потеряем, используя наши алгоритмы?
Ответ на первый из поставленных нами вопросов дает следующий график.

Мы видим, что точность классификации зависит от выбора уровня вероятностного барьера, повышаясь при его увеличении. Это логично, так как чем выше вероятность, с которой мы хотим определять пользователей, которые не прочтут очередное письмо, тем меньшее количество таких пользователей будет находить алгоритм, а значит и меньше будет ошибчно проклассифицированных пользователей.
Под ошибкой классификации мы понимаем тот случай, когда алгоритм относит пользователя к маловероятным к прочтению, тогда как на самом деле пользователь откроет письмо (возможно, чтобы отписаться). Например, при барьере в 95% мы будем допускать ошибку классификации в 1,2%. Это означает, что среди той группы клиентов, которым мы не будем рекомендовать отправлять письмо
1,2% пользователей его откроют, то есть в этой группе пользователей можно ожидать коэффициент прочтения писем на уровне 1,2%.
Как мы видим из графика, ошибка классификации для высокого уровня барьера (99% и выше) невелика и составляет меньше половины процента.
Второй вопрос: какую же часть пользователей можно дополнительно отфильтровать используя наши методы? Это зависит от специфики клиентской базы и других факторов, и может колебаться в значительных пределах. Например, при выборе уровня вероятности в 95% можно получить рекомендацию к исключению из рассылки от 30% до 50% тех пользователей, которые совершали какие-то активные действия в течение последних 90 дней. Аналогично при барьере в 99% этот показатель может колебаться от 5% до 10% и выше.
Ответ на третий вопрос напрямую зависит от того, какой результат мы получаем при ответе на второй вопрос. В целом, можно сказать, что мы будем терять в открытиях обратно пропорционально выбору вероятностного барьера. Иными словами, если мы выбираем барьер в 99%, то при этом потеряем в открытиях где-то на 1%, а вот если уменьшим барьер до 95%, то точно потеряем процентов 5, но может быть и больше (7-8).
Таким образом, чем выше мы выбираем вероятностный барьер, тем меньше будет потерь в прочтениях и переходах, при этом меньшую часть пользователей мы отбросим, и наоборот. Какую стратегию следует выбрать – это индивидуальный вопрос, который может быть решен только с учетом всех факторов. Описанная нами технология работы классификаторов, основанных на применении алгоритмов искусственного интеллекта, дает, по крайней мере, качественную картину того, на что вы можете расчитывать применяя подобные технологии для своих целей.
Если вы хотите более подробно ознакомиться с технической стороной наших алгоритмов – читайте статью “Прогнозирование активности пользователей с алгоритмом Machine Learning и языка R” в нашем блоге.
Хороший, плохой, злой: как Яндекс использует нейросети для борьбы со спамом и матом

Любой сайт, где пользователи могут сами публиковать контент — потенциальная площадка для спама, мошенничества и нецензурной лексики. У Яндекса есть несколько сервисов (например, Яндекс.Карты, Яндекс.Район, Яндекс.Кью и Кинопоиск), где любой может оставить комментарий, поэтому команда Антиспама создает инструменты для борьбы с недопустимым контентом.
К автоматическим классификаторам разработчики предъявляют несколько требований:
- Точность. Система должна верно отмечать «плохой» контент, не удаляя при этом нейтральные посты без спама и мата.
- Полнота. Одной точности недостаточно: «автомодератор» может функционировать без ложных срабатываний, но при этом пропускать часть спама и ругательств. Поэтому важна полнота — это доля плохого контента, который система выявляет как плохой.
- Скорость. Даже если спам провисел на сайте несколько минут, его могли увидеть сотни людей, а это отрицательно сказывается на репутации самого сервиса — поэтому система должна работать как можно оперативнее.
Эффективность Антиспама проверяют асессоры — они отсматривают выборки контента и оценивают решения машины. Сейчас система, проверяющая комментарии, работает с помощью нескольких инструментов:
Чистый веб
Чистый веб — сервис, который защищает от спама все продукты Яндекса, где публикуется созданный пользователем контент. В его основе лежат наработки, которые изначально создавались для фильтрации взрослого контента в поисковых запросах. Например, чтобы по запросу «медсестра» поисковик показывал только сотрудников больниц, а не кадры из фильмов для взрослых.
Тексты проверялись с помощью собранных вручную и регулярно пополняющихся словарей обсценной лексики. На их основе разработчики обучали модели и классифицировали запросы на те, где можно показывать взрослый контент, а где — нет. Однако чем больше продуктов Яндекса требовало регулярной модерации контента, тем важнее было лучше автоматизировать этот процесс.
Умное кэширование
Что касается спама, то основная сложность в его «поимке» — это не определение контекста, а скорость его распространения. Для того чтобы система не удаляла спам автоматически, злоумышленники незначительно меняют сообщения перед отправкой: добавляют новые слова, заменяют символы.
Для выявления таких сообщений используют вероятностный метод понижения размерности многомерных данных — Locality-sensitive hashing (LSH). Каждый проверяемый текст разделяется на последовательности из n символов, и по их хэшам строится LSH-вектор документа. Благодаря этому машина сравнивает не сами тексты, а их векторы. Это позволяет эффективно вычислять спам, даже если каждое новое сообщение чем-то отличается от предыдущего.
Теперь как только одно из сообщений помечается системой или человеком как спам, остальные похожие удаляются автоматически. Это сокращает время обработки комментариев — потенциально вредоносные сообщения не висят на страницах в ожидании вердикта.
Толокеры и асессоры
Хотя система и учится самостоятельно вычислять спам, иногда она нуждается в помощи или перепроверке. Это касается тех случаев, когда важно не просто удалить пост с ругательствами, а верно оценить контекст. Иногда спамеры рекламируют свои услуги в отзывах у конкурентов, пишут бессмысленный набор символов или просто по ошибке оставляют комментарий не о той организации (например, жалуются на маникюрный салон в отзывах на ресторан).
Поскольку машина не всегда точно улавливает контекст, сложные случаи перепроверяют вручную. Толокеры (пользователи сервиса Толока, созданного для обучения ИИ) и асессоры (специалисты, анализирующие работу поисковой системы) оценивают тексты, в которых классификатор не увидел ошибок, и благодаря этому помогают обучать систему.
Классификатор хороших текстов
Классификатор хороших текстов позволяет автоматизировать часть работы, которой раньше занимались люди. Первые модели работали по такому принципу: они разбивали текст на слова, приводили каждое слово в начальную форму (иначе говоря, выделяли леммы) и анализировали их с помощью специального «словаря хороших лемм», служебные слова при этом не учитывались.
Логика такой системы заключалась в том, что если сообщение состоит только из «хороших» слов, то и посыл его скорее всего не будет содержать оскорблений — однако современные модели работают умнее. Разметкой грубостей в классификаторе занимается нейросеть BERT, созданная для обработки естественного языка. Она улавливает слова в контексте и помогает выявлять оскорбления даже там, где не используются грубые слова.
Антимат
Правила сервисов Яндекса не позволяют использовать нецензурную лексику, поэтому машина должна уметь вычислять и ее тоже. Проблема в том, что мат очень разнообразен: мало того, что от нескольких корней можно образовать огромное число слов, так еще и каждое из них можно написать по-разному: «запикать» часть символов звездочками, добавить транслит, переставить буквы местами.
Поэтому недостаточно составить словарь «плохих слов». Вместо этого Яндекс научил машину самостоятельно вносить шум в мат и ругательства — генерировать варианты, на которые может хватить фантазии пользователей. Благодаря этому система может подозрительные комбинации символов, даже если их нет в словарях. В этом случае цель системы не в том, чтобы перебрать все возможные варианты, а в том, чтобы комментатору стало лень тратить усилия на придумывание такого оскорбления, которое не сможет придумать машина.
Заключение
Сегодня машина обрабатывает до 90% контента, но все равно нуждается в перепроверке человеком. Конечно, при желании пользователи могут так завуалировать оскорбление, чтобы система ничего не распознала, но большую часть спама и негатива нейросети уже научились удалять быстро и точно.
Новая система ИИ будет отфильтровывать спам в интернете
Instagram внедряет ИИ для распознавания травли

Facebook как один из мировых лидеров в разработке технологий искусственного интеллекта нашёл прикладное применение для этих программ: фильтрация общения людей. Передовые инновации внедряют в социальной сети Instagram (см. пресс-релиз Instagram, а также репортаж в Time с комментарием Йоава Шапиры, ведущего разработчика нейросетевых классификаторов травли).
Самая интересная из новых функций — что «грубого человека» можно заблокировать так, что он даже этого не заметит. Пользователь продолжит хамить, но его опубликованные сообщения будут видны только ему одному. Это идеальный вариант, чтобы не блокировать грубияна и не обострять ситуацию. Впрочем, конкретно эта функция не связана с системой ИИ.
Как сказано в пресс-релизе, в ближайшее время Instagram представит новые функции, «направленные на сдерживание онлайн-буллинга» (травли). Это происходит в то время, когда во всём мире растут призывы усилить контроль за такими платформами, как Facebook и Twitter, на фоне критики за распространение ненависти и фейковых новостей, а также за широко распространённую агрессию и грубость в комментариях.
Instagram с аудиторией в 500 миллионов человек является платформой, ориентированной на изображения. Здесь пользователи размещают фотографии и видео, которые затем прокомментируют другие пользователями.
Сейчас компания заявила, что в течение многих лет использует ИИ для мониторинга травли и вредоносного контента, а теперь представляет интерфейс непосредственного взаимодействия этого ИИ с пользователями.
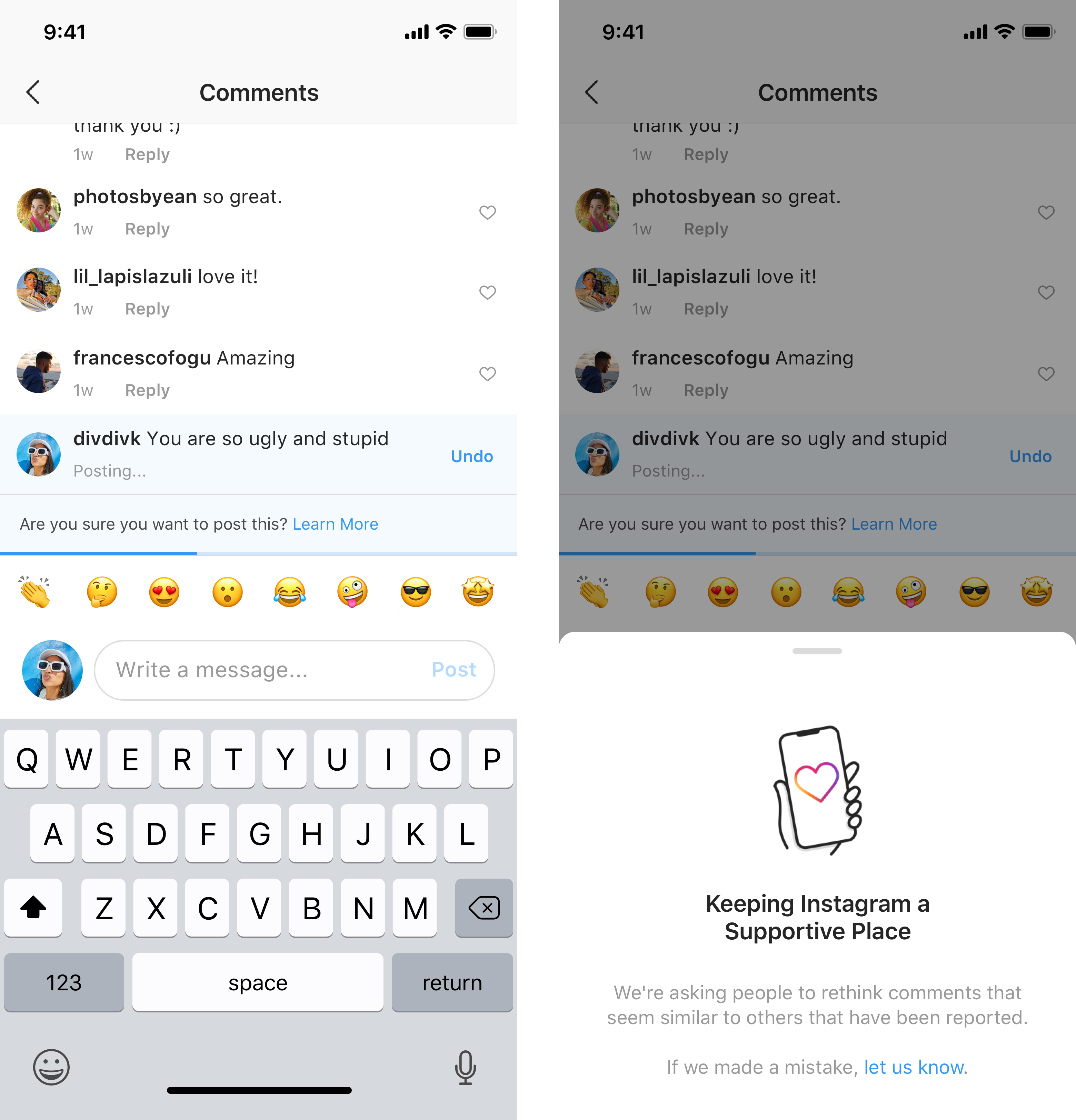
Две новые функции
Во-первых, это технология мгновенного обнаружения, когда пользователь пытается опубликовать что-то оскорбительное. Система будем выдавать предупреждение перед публикацией. «Это вмешательство даёт людям возможность задуматься и отменить свой комментарий, — говорится в заявлении руководителя Instagram Адама Моссери. — Из ранних тестов этой функции мы обнаружили, что она побуждает некоторых людей отменить свой комментарий и поделиться чем-то менее вредным, как только у него появляется возможность подумать».
Другая новая функция — «Ограничение» (Restrict) — направлена на ограничение оскорбительных комментариев в ленте пользователя. «Мы слышали от молодых людей в нашем сообществе, что они не хотят ни блокировать, ни удалять из фоловеров, ни сообщать о хулигане, потому что это может обострить ситуацию, особенно если они взаимодействуют с ним в реальной жизни», — сказал Моссери.
Теперь появился новый вариант: сделать так, что посты обидчика будут видимы только ему. Грубияна переводят в «ограниченный» (restricted) режим, то есть он буквально становится «ограниченным пользователем».
Шаг 1. Вы видите комментарий грубияна
Шаг 2. Вы удаляете комментарий и переводите грубияна в режим Restricted
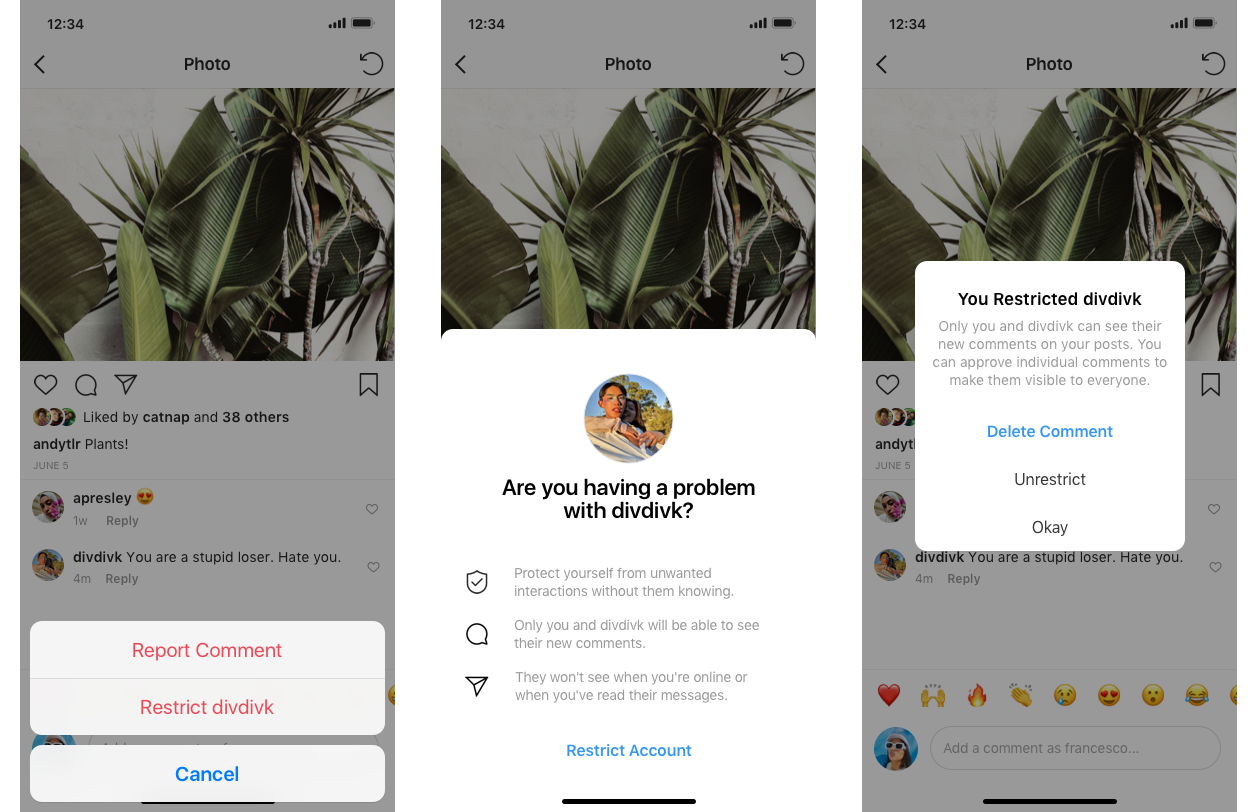
«Ограниченные люди не смогут видеть, когда вы активны на Instagram или когда вы прочитали их прямые сообщения», — добавил Моссери.
Шаг Instagram должен помочь защитить особенно подростков. Согласно опросу, опубликованному исследовательским центром Pew Research Center в прошлом году, 72% подростков США заявили, что они использовали Instagram.
Запугивание и травля — лишь один из многих фронтов, на которых от социальных сетей требуют действий в последние годы. Растут призывы к регулированию таких платформ в связи с распространением сообщений, разжигающих ненависть, и фейковых новостей.
Такие компании, как Facebook, в ответ на это начали изменять политику и внедрять функции, направленные на повышение прозрачности и безопасности. Пока получается с переменным успехом, но без давления общества не было бы и этого.
Искусственный интеллект
В интервью Time представители Instagram сказали, что для фильтрации грубого поведения и издевательств в будущем они полагаются на технологии искусственного интеллекта, чтобы полностью искоренить травлю, издевательства и неуважение. Молодые люди сейчас зачастую запуганы и стесняются, бояться сообщить о неподобающем поведении, дать отпор группе хулиганов или заблокировать их. В будущем им не придётся этого делать: система ИИ сама позаботится о слабых.
Создание искусственного интеллекта для борьбы с грубостью — это своеобразный технический Эверест, пишет Time. Это означает обучение машин пониманию проблемы со сложными нюансами. Instagram также должен опасаться проблем со свободой слова, поскольку инженеры создают инструменты, которые оптимизированы для поиска того, что надо, не фильтруя лишнего: «Я беспокоюсь, что если мы не будем осторожны, то можем переступить грань», — говорит Адам Моссери, глава Instagram. Однако он готов принимать решения, которые означают снижение активности пользователей в Instagram, если это повышает безопасность.
Сайт для обмена фотографиями практически с самого начала начали использовать извращенцы. 20-летние основатели компании Кевин Систром и Майк Кригер целыми днями лично удаляли неприятные комментарии и блокировли троллей. Затем они применили инструмент ИИ, известный как DeepText, разработанный для понимания и интерпретации языка.
Инженеры Instagram впервые использовали DeepText в 2016 году для поиска спама. В 2017 году его обучили находить и блокировать оскорбительные комментарии, включая расовые оскорбления. К середине 2018 года программа — по сути, набор нейросетей, — обучили находить в комментариях также и травлю, то есть умышленную грубость. В октябре 2018 года компания объявила, что система ИИ будет анализировать не только комментарии, но и сами посты.
Когда инженеры хотят научить машину выполнять ту или иную задачу, они начинают с создания обучающего набора — набора простых терминов, набора материала, который поможет машине понять правила её новой работы. В этом случае поиск начинается с того, что модераторы сортируют сотни тысяч фрагментов контента и решают, содержат они издевательства или нет. Они помечают их и вводят примеры в так называемый классификатор. Конечно, эти начальные примеры не могут охватить всё, с чем столкнётся классификатор в реальной жизни. Но он помечает контент и как люди-модераторы тоже учится на дополнительных примерах. В идеале, с помощью инженеров, настраивая свои привычки изучения, он становится всё лучше и лучше с течением времени.
Сегодня Instagram использует для сканирования контента три отдельных классификатора травли. Один обучен на распознавание оскорбляющего текста, второй — фотографий, третий — видео. Классификаторы уже живут в нормальном режиме: работают, ищут и помечают контент. Тем не менее, они пока находятся «на довольно ранней стадии разработки», говорит ведущий инженер Йоав Шапира. Другими словами, они пропускают много издевательств, и не обязательно находят оскорбления. То есть допускают много ложноположительных и ложноотрицательных срабатываний.
Распознать грубости сложнее, чем обучить нейросеть, например, находить наготу, поскольку гораздо легче распознать, когда кто-то на фотографии не носит штаны, чем распознать широкий спектр поведения, которое может считаться издевательством. Исследования киберзапугивания сильно различаются в своих выводах о том, сколько людей испытали его, от 5% до 72%, отчасти потому, что никто не согласен с тем, что это такое. «То, что делает издевательства настолько трудными для решения, заключается в том, что определение настолько отличается у разных людей», — говорит Карина Ньютон, глава по публичной политике Instagram.
Другими словами, какое-то замечание может глубоко оскорбить одного человека, а другой воспримет его абсолютно нейтрально и спокойно, то есть вообще не примет за оскорбление.
А инженерам нужно дать чёткие инструкции, что квалифицируется как травля, а что нет, чтобы построить надёжный набор данных для обучения.
Формы издевательств в Instagram со временем изменились, пишет Time. Есть много того, что можно назвать «старомодными издевательствами»: это самые распространённые комментарии, оскорбления и угрозы, согласно собственным исследованиям Instagram. Некоторые из них легко обнаружить. Текстовый классификатор, например, хорошо обучен искать предложения типа «Ты уродливая задница, сука с зубами» (you ugly ass gapped tooth ass bitch) или «Твоя дочь шлюха» (Your daughter is a slag). Но сленг меняется со временем и в разных культурах, особенно в молодёжной. А для выявления агрессивного поведения требуется осмысление полных предложений, а не только нескольких слов. Есть разница между «Я приду позже» и «Я приду позже, что бы ты ни говорил».
Пользователи Instagram также становятся жертвами агрессивного поведения, которое выходит за рамки слов. На сайте есть так называемые «страницы ненависти», анонимные учётные записи, посвященные высмеиванию людей. Парень может поставить тег своей бывшей девушки на сообщениях, где он с другими девушками. Или девушка может пометить кучу друзей в сообщении и демонстративно исключить кого-то. Другие могут сделать скриншот чьей-то фотографии, изменить её или просто издеваться над ней в групповом чате. Есть повторяющийся контент как оскорбление — например, размещение одного и того же смайлика на каждой фотографии, которую публикует человек, что имитирует преследование. Многие подростки находят неловкие фотографии или видео со своим участием, размещённые без их согласия, или оказываются предметом голосования HotOrNot (примерно такую голосовалку под названием Facemash создал Марк Цукерберг, будучи студентом Гарварде на веб-сайте, который позже был переименован в Facebook).
В рамках своих усилий по разработке эффективного ИИ Instagram сейчас проводит опрос тысяч пользователей в надежде лучше понять все формы, которые могут принимать издевательства, в глазах аудитории. Ответы также помогут Instagram оценить распространённость издевательств на платформе. Эти данные впервые будут обнародованы в этом году.
Сейчас для обучения классификатора команда Шапиры разбила травлю на семь подкатегорий:
- оскорбления,
- пристыживания,
- угрозы,
- атаки на личность,
- неуважение,
- нежелательные контакты,
- измены.
Грандиозный план заключается в создании искусственного интеллекта, который обучен понимать каждую концепцию.
Поскольку издевательства могут быть привязаны к внутреннему контексту и тому, насколько хорошо два человека знают друг друга, инженеры Instagram также исследуют способы анализа активности и историю пользователей. Например, слово «хо», может быть классифицировано как издевательство, когда мужчина говорит это женщине, но не когда женщина использует его для приветствия друга. Точно так же, если кто-то однажды скажет «потрясающая картинка», это может быть комплиментом. Но если они говорят это на каждой фотографии, которую публикует человек, то это начинает выглядеть подозрительно.
Инженеры извлекают выгоду из сигналов, которые помогают выявить эти отношения: часто ли две учётные записи ставят метки друг у друга? Кто-нибудь из них когда-то в прошлом блокировал другого? Является ли имя пользователя похожим на того, кто был заблокирован в прошлом? Есть ли признаки скоординированных действий с другими пользователями?
Когда дело доходит до фотографий и видео, у классификаторов меньше практики и они менее продвинуты. Инженеры и модераторы пока идентифицируют шаблоны, но некоторые ориентиры уже появились. Например, экран, разделённый на две половины, часто является признаком издевательств, особенно если машина обнаруживает на одной стороне человека, а на другой — животное. Как и фотография трёх человек, где лицо одного из них перечёркнуто. Команда также учится понимать такие факторы, как осанка. Скорее всего, фотография была сделана без согласия, если она выглядит как снимок «под юбкой». Если один человек стоит, а другой находится в позе жертвы, это красный флаг.
Каждую неделю исследователи отчитываются о своих находках, и почти каждую неделю появляется какая-то новая форма издевательств, которую инженеры раньше и не думали искать, говорит Шапира. Но Facebook и Instagram уверены, что способны справиться с этими проблемами.
Неизвестно, сколько из примерно 1200 сотрудников Instagram или примерно 37 700 сотрудников Facebook работают над проектом.
Ведущий разработчик также отказался сообщить текущий процент ошибок классификаторов и объём контента, который они помечают для модераторов. «В ближайшие год-два будет намного лучше», — только сказал Йоав Шапира.
Интересные письма в спаме
Здравствуйте уваж пользователи сайта!я вообще мало захожу на пк в своей почте в эту папку спам
Но сегодня вот решил заглянуть-что мне там напреходило
Как ни странно там оказалось очень много писем с просьбой получить какие-то денежные переводы от каких то неизвестных мне людей и каких-то неизвестных названий то ли компаний то ли просто вымышленных названий
Вот к примеру:
Вам презен 70 000 от Лев Аксаков (Mr Mattress)
“Pokerpayer”
⚁
Кому: витя
9 января, 20:02
Письмо попало в папку «Спам», потому что оно похоже на сообщения, которые ранее были отфильтрованы нашей системой как спам. Подробнее Не нажимайте на это видео-не знаю к чему это может привести
https://youtu.be/EbCU4b9HDq0
Хватит работать на дядю-Работай на себя!
Отправь босса в отставку и подари себе финансовую независимость!
Стань хозяином своей жизни и получай 50 000-70 000 в неделю.
Ваша финансовая независимость тут
Или такое
[Themarketects] Платеж успешно проведен. : 8OOO RUR
Александр Бухало
⚁
Кому: витя
29 декабря 2016, 18:55
Письмо попало в папку «Спам», потому что оно похоже на сообщения, которые ранее были отфильтрованы нашей системой как спам. Подробнее
Вам бесплатно открыт доступ к нашей системе заработка.
Система X-CASH.
Заработок от 8 000 р в день.
Ваш ID: 6493
Инструкции и регистрация тут
или ещё
Я переведу вам сейчас 8 ООО р. Счет номер: 41861 Malone Engineering
Кузьма Митин
⚁
Кому: витя
29 декабря 2016, 0:27
Письмо попало в папку «Спам», потому что оно похоже на сообщения, которые ранее были отфильтрованы нашей системой как спам. Подробнее
Здравствуйте, Виктор!
От этого предложения вы точно не откажитесь.
С уважением,
Феликс Митин.
В последнем интересно Кузьма Митин-Феликс Митин-одно сообщение,а имена другие
Что бы это значило-меня взломали,точнее мою почту?
или просто хотят выведать какие-либо данные обо мне,прося перейти на сайт
или ещё что
Кто сталкивался с такими письмами-объясните мне -что это всё означает
—–
Loco Lupe’s Mexican
1842 Harper Road
501.623-3737 / +1-501.623-3737
———-
Pokerpayer
128 N. Harding St.
Wayne, New Jersey
Добавлено через 1 минуту
не нажимайте на видео выше,я его скопировал с письма-не знаю что это за ссылка
Как обойти спам фильтры
 Обход спам-фильтров очень необходим. Важное условие, чтобы не угодить в спам: свежая база, около 500 подписчиков. Нажатие на кнопку «Спам» подрывает репутацию отправителя IP – адреса и последующую доставляемость писем.
Обход спам-фильтров очень необходим. Важное условие, чтобы не угодить в спам: свежая база, около 500 подписчиков. Нажатие на кнопку «Спам» подрывает репутацию отправителя IP – адреса и последующую доставляемость писем.
Необходимо знать: как обойди спам фильтры при рассылке, особенно авторам, желающим улучшить эффективность рассылки, качественные взаимоотношения с целевой аудиторией.
Обязательные способы обхода спам фильтров:
Пользуйтесь своим доменом. Указав свой email-адрес, как потенциального отправителя, провайдер регистрирует ваш домен сайта.
Пример: правильного написания —vacheimya@vashdoman.ru; неправильного — vacheimya@gmail.com адрес: noreply@, т. е. нечитаемый ящик. Вы сделали первый шаг против спама.
Пройдите регистрацию на 2-х сервисах почтовых провайдеров, добавьте свой домен, пройдите модерацию: postoffice.yandex.ru/; postmaster.mail.ru/ . Сообщите о своей готовности, использовать «белые» рассылки, попросите рекомендации, как стать лучшими. Шаг второй- Вы на 50% можете обойти антиспам.
Сделайте «лицензионной» вашу базу, добавьте ключевые технические параметры (DKIM-подпись, SPF-запись, DMARC-спецификаци) . Третий шаг придал Вам уверенность в победе над спамом. Пользуйтесь поддержкой функции double opt-in-. Активационное письмо отправляется подписчику по спец. ссылке. Шаг четвертый — Вы одержали победу.
Обязательно используйте цифровую подпись со спец. ключами SPF, DKIM, пропишите DMARC-политику для собственного сайта. Подпись подтверждает, что лицо проверенное. Пятым шагом – Вы неприкосновенны, достойно сделали обход фильтров.
Дополнительный список рекомендаций пользователям, как обойти спам фильтры, не попасть в «черный список».
- Равномерное отправление рассылок, через неделю, десять дней.
- Сохраняйте тематическую рассылку.
- Будьте доброжелательными, не пишите текст с ошибками.
- Не шлите рассылку, не подписавшимся клиентам.
- Употребляйте слова Subscribe / Unsubscribe, вместо Remove, читаемые автоматическими системами.
- Заголовки: «Free», «Money», «Respond Now!» обычно применяют для спам-рассылок, вместо (Subject).
- Наиболее значимые для вас слова пишите через тире, пробел. Например:
« и н т е р н е т», «и-н-т-е-р-н-е-т». Рекомендуется также заменять русские буквы: е, а латинскими. Антиспам не поймет нововведения.
Спам — рассылка — отправление письма пользователю без его согласия. Получая частые, нежелательные сообщения, подписчик совершает действие, прикладываясь к кнопке «спам». Не попадает ваша информация в инбокс, происходит сначала частичная, затем полная блокировка вашего домена почтовыми сервисами.
Вы тоже можете попасть в спам, получить жалобу, не являясь профессиональным спамером. Несмотря на то, что работаете добросовестно по правилу: имеете добро на отправку корреспонденции у подписчиков.
Спам фильтры — автоматически определяют спам программным обеспечением. Используются серверами, пользователями на конечном этапе, фильтруют, отделяя переписку хорошего качества от спам — рассылок. В сложной многоуровневой системе фильтры фильтруют письма, направляя их в папки «Входящие» (инбокс), или «Спам». По количественному показателю доставляемости писем, виден результат работы системы. Присутствует: тройная защищенность для подписчиков и тройная преграда для отправителей рассылок.
Google Spam Update: Анализ алгоритма, что изменилось в борьбе со спамом и стоит ли беспокоиться





23 июня Google объявил о запуске так называемого спам-апдейта — алгоритме, отвечающем за борьбу со спамом. Кому стоит беспокоиться и как не потерять позиции после подобных апдейтов?

Сам анонс не содержит подробной информации, какой именно спам учитывается в этом апдейте. Google оставил лишь ссылку на статью по борьбе со спамом.
As part of our regular work to improve results, we’ve released a spam update to our systems. You can learn more about our efforts to fight spam in this post:https://t.co/piCLhbZPkH
— Google SearchLiaison (@searchliaison) June 23, 2021
Но позже, все же поделился еще одной ссылкой на правила в отношении контента в Google поиске. Текущая статья написана как агрегация релевантной информации со всех документов Google по работе поисковика с веб-спамом.
Что считается поисковым спамом?
Веб-спамом считается всевозможные техники обмана поисковой системы и пользователей с целью монетизации, или воровства персональных данных с дальнейшей их монетизацей. Сюда входят:
- Создание фишинговых и других мошеннических сайтов
- Установка вирусов
- Дорвеи и клоакинг, сомнительные редиректы
- Автосгенерированный контент с избытком ключевых слов
- Скрытый текст
- Продажа ссылок
- Раздражающие рекламные блоки
- Злоупотребление микроразметкой
- Участие в схемах обмена ссылками
- Публикация скопированного контента
Это все пресекалось и раньше, что изменилось?
Поисковые системы, действительно, борются с веб-спамом уже многие годы. Но на текущий момент очень развился искусственный интеллект и машинное обучение, что помогает более эффективно выявлять спам. Плюс, алгоритмы антиспама внедрились в различные этапы поиска. Google использует “интеллектуальный механизм борьбы со спамом”.
- Сначала классификаторы Google определяют спам еще на этапе краулинга и большую часть не пускают в индекс. Это касается как тех страниц, о которых стало известно благодаря ссылкам, так и тех, о которых стало известно из Sitemap или Google Search Console.
- Второй эшелон антиспама работает с проиндексированными страницами и в случае автоматического обнаружения спама не дает ему появляться в верхних результатах поиска. Здесь используется ИИ и фильтрует 99% спама.
- Оставшийся спам может фильтроваться на третьем этапе уже вручную, с помощью специально обученных асессоров (так называемые ручные санкции).
Другими словами, изменилась архитектура алгоритма, плюс подключили к работе ИИ. Кстати, инструменты мониторинга SERP не зафиксировали крупных изменений на выдаче.
Похоже, все июньские апдейты сильно связаны между собой. Один из сигналов в Google Page Experience Update это как раз “безопасный просмотр”, что непосредственно относится к описываемым Google пунктам по ссылке в анонсе про Spam Update.
Кому стоит беспокоиться?

В первую очередь апдейт преследует безопасность пользователей и направлен на мошеннические действия, которые используют чаще хакеры и черные оптимизаторы, ломая сайты и подкладывая ссылки, создавая дорвеи и обманный контент. Если вы не входите в группу таких вебмастеров, то беспокоиться стоит намного меньше. Скорей всего, для вас ничего не изменится.
Однако, стоит все же пересмотреть свои контент- и ссылочные стратегии, провести аудит рекламных блоков и партнеров. И чтобы всегда оставаться в ТОПе, создавайте контент для пользователей, а не для поисковых систем.
Борьба со спамом и машинное обучение
29 декабря 2014
Как явление нежелательная массовая рассылка (спам) возникло ещё до появления электронной почты, но именно благодаря интернету оно приняло глобальные масштабы. Современные методы борьбы со спамом в корне отличаются от примитивных почтовых фильтров. В них используются технологии машинного обучения и методы глубокого анализа миллиардов писем, позволяющих изучать работу почтовых серверов как единый процесс. Ведущую роль в этом играют новые подходы к обработке «больших данных», реализованные в виде набора технологий, специфичных для каждого программного продукта.
Причины и масштабы спама
В отличие от бумажной корреспонденции, плата за каждое сообщение в сети отсутствует. Для спамера нет принципиальной разницы между тем, отправить сто писем или сто тысяч – была бы актуальная база адресов электронной почты. Её можно купить или собрать роботом по веб-форумам, а дальше рассылка не будет стоить ровным счётом ничего. Многие письма не дойдут до получателя, а большую часть из полученных – проигнорируют. Однако при разовых затратах на БД, минимальных рисках и колоссальных объёмах, прибыль приносит даже то малое количество людей, которое всё же отреагирует на рассылку.
 Спам существовал всегда, но действительно массовыми рассылки стали только за счёт интернета.
Спам существовал всегда, но действительно массовыми рассылки стали только за счёт интернета.
Получается, что спам выгоден тем, кто его рассылает и тем, кому временное увеличение продаж важнее репутации. Например, если товар нельзя эффективно реализовать традиционным способом из-за его низкого качества или незаконного характера оборота. Больше всего от спама страдают даже не рядовые пользователи и частные предприниматели, а провайдеры и крупные организации.
Ежедневно в мире через почтовые серверы проходит свыше ста миллиардов писем. Более двух третей из них составляют нежелательные рассылки. Сходную оценку приводит Symantec и другие ведущие компании в сфере ИБ. На долю США приходится 13,4% всех спам-рассылок в мире, а Россия занимает «второе почётное место» с результатом 6%.
Эволюция методов борьбы со спамом
Поначалу бороться со спамом пытались с помощью составления простых фильтров – «чёрных» и «белых» списков ключевых слов. В первый попадали слова, характеризующие недобросовестного отправителя, тему массовой рассылки или текст рекламного сообщения. Во второй – адреса друзей и знакомых, чтобы их письма случайно не попали в категорию «спам». Эффективность таких фильтров была очень низкой, поскольку спамеры постоянно меняли темы сообщений, подставляли ложные адреса отправителя, использовали замену отдельных букв или просто делали вложение с картинкой вместо текста.
 Простой отсев по ключевым словам был первой технологией фильтрации.
Простой отсев по ключевым словам был первой технологией фильтрации.
Поэтому на смену грубым методам отсева пришли вероятностные модели. В них уже не столько искались определённые слова, сколько оценивался шанс принадлежности письма к нежелательной рассылке сразу по многим признакам. Первые работы о фильтрации спама с использованием вероятностного классификатора, основанного на положениях Теоремы Байеса, появились в девяностых годах прошлого века. Такие алгоритмы помогали точнее определить риск принадлежности письма к нежелательной корреспонденции, сопоставляя его текст и метаданные с другими сообщениями.
Современные технологии фильтрации спама
Байесовская фильтрация спама стала предвестником целого ряда технологий обработки «больших данных», в которых повышение качества вероятностного анализа достигается за счёт использования накопленных статистических данных и другой взаимосвязанной информации. Спамеры адаптируют методики рассылки к новым способам её отсева, поэтому в чистом виде ни один алгоритм фильтрации долго не работает. Вместо этого провайдеры и фирмы, специализирующиеся на защите данных, развивают методы машинного обучения.
 Именно технологии анализа «больших данных» позволили снизить долю спама в последнее время.
Именно технологии анализа «больших данных» позволили снизить долю спама в последнее время.
Высокую оценку роли технологий Big Data в развитии современных методов борьбы со спамом дали Виктор Майер-Шенбергер и Кеннет Кукьер – авторы книги «Большие данные. Революция, которая изменит то, как мы живем, работаем и мыслим».
По сути, большие данные предназначены для прогнозирования. Обычно их описывают как часть компьютерной науки под названием «искусственный интеллект» (точнее, её раздел «машинное обучение»). Такая характеристика вводит в заблуждение, поскольку речь идет не о попытке «научить» компьютер «думать», как люди. Вместо этого рассматривается применение математических приемов к большому количеству данных для прогноза вероятностей, например, что электронное письмо является спамом.
Эти системы работают эффективно благодаря поступлению большого количества данных, на основе которых они могут строить свои прогнозы. Более того, системы спроектированы таким образом, чтобы со временем улучшаться за счет отслеживания самых полезных сигналов и моделей по мере поступления новых данных. Спам-фильтры разрабатываются с учетом автоматической адаптации к изменению типов нежелательных электронных писем, ведь программное обеспечение нельзя эффективно запрограммировать таким образом, чтобы блокировать слово «виагра» или бесконечное количество его вариантов.
Текущие методы интеллектуальной фильтрации используют одновременно два разных подхода. В первом из них повышение эффективности вероятностной оценки писем достигается за счёт добавления в базы данных большой выборки предварительно отсортированных вручную сообщений, относящихся к спаму, и обычной корреспонденции. Во втором случае ключевую роль играет расширенный статистический анализ с целью выявление закономерностей в самих рассылках.
Оба метода применяются в технологиях обработки «больших данных», но второй считается более перспективным. Он повышает точность распознавания, снижает количество ручных манипуляций и позволяет быстрее реагировать на новые методы навязчивой рекламы.
 Визуальное представление почтового трафика в виде графа отражает характер переписки людей и наглядно показывает массовую рассылку.
Визуальное представление почтового трафика в виде графа отражает характер переписки людей и наглядно показывает массовую рассылку.
Во всех современных решениях для борьбы со спамом применяется многоуровневая фильтрация, состоящая, как минимум, их этих двух этапов. Для обновления списков используется статистика, собранная по всему миру. Поэтому отсеивание писем по репутации на основе «чёрных» и «белых» списков IP-адресов – один из самых эффективных способов блокирования рассылки нежелательной корреспонденции. Он обеспечивает быструю реакцию и низкую нагрузку на систему антиспама. Ей не приходится принимать и обрабатывать каждое письмо – многие отсеиваются ещё на этапе соединения.
Противостояние спамеров и систем фильтрации сообщений относится к извечной проблеме щита и меча: они эволюционируют параллельно под влиянием друг друга. Однако с появлением технологий быстрого выявления рассылок по статистическому анализу больших выборок писем в этой борьбе наметился переломный этап. Доля спама в почтовом трафике стала снижаться и продолжает падать по мере внедрения провайдерами решений, основанных на методах Big Data.
За прошедший год количество спама в деловой корреспонденции впервые снизилось на три процента, или на целый миллиард рекламных писем в абсолютных значениях. Предварительные итоги этого года подтверждают дальнейшее очищение почтового трафика. Чем больше операторов связи и ИТ-отделов компаний будут использовать продвинутые методы фильтрации спама, тем сложнее станет его распространять. Окончательная победа произойдёт в тот момент, когда рассылку рекламы перестанут заказывать из-за резко упавшей результативности.
